사물인터넷(IoT) 시대를 맞아 빅데이터 속에서 실시간으로 인사이트를 얻기 위해 다양한 방법이 강구되고 있다. 6일 본지 취재 결과 최근 관련업계에서는 서로 연결된 각종 기계로부터 쏟아지고 있는(machine-generated) 데이터에 대한 관심이 점차 늘어나고 있다. IDC는 오는 2018년까지 IoT에서 생성된 데이터의 40%가 보관되고 프로세스를 거쳐 분석될 것으로 예상하고 있다. 빅데이터가 IoT와 결합하면서 폭넓은 분야에서 데이터 분석과 활용이 보편화될 것으로 전망된다.
이에 따라 보다 빠르고 명확한 의사결정으로 경쟁에서 앞서기 위해 ‘실시간 분석’에 대한 니즈도 급증하고 있다. ‘온라인 분석’은 데이터의 생성 시점과 분석 시점의 구분이 없는 반면, ‘실시간 분석’은 데이터가 생성되는 시점에 최대한 가깝게 분석이 함께 이뤄진다. 수많은 센서나 소셜미디어에서 생성되는 시계열(time series) 데이터를 그 대상으로 하며, 특히 각종 기계로부터 생성되는 로그데이터가 주재료가 되고 있다.
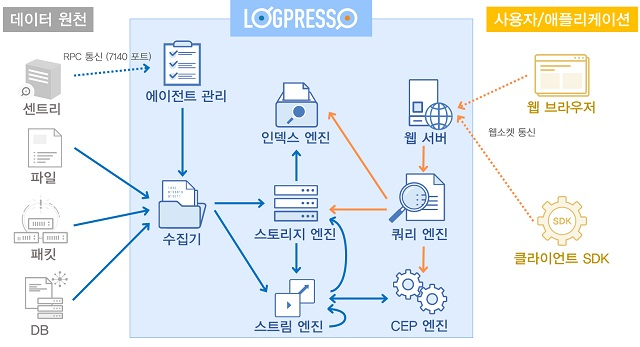
소프트웨어(SW) 벤더들은 ‘빅데이터’와 ‘실시간’이라는 두 축을 모두 지원하기 위해 다양한 형태의 솔루션을 선보이며 이 새로운 시장을 공략하고 있다. 공통적으로 빠른 색인(indexing)을 지원하며, 크게 컬럼형 데이터베이스관리시스템(DBMS)에서 파생된 유형과 로그처리시스템에서 발전된 유형으로 구분할 수 있다.
컬럼형DBMS에서 파생된 유형의 경우 DML(데이터조작언어) 가운데 수정(update)과 삭제(delete)를 지원하지 않는 대신 입력(insert)과 검색(select)을 위한 성능을 극대화시키는 등의 방식을 취한다. 로그처리시스템에서 발전된 유형의 경우 NoSQL DB처럼 스키마(schema)를 고정하지 않고 로(raw)데이터 자체를 실시간 인덱싱하고 향후 분석 대상을 재정의하는 스키마리스(schema-less) 형태로 저장한다.
컬럼형DBMS에서 파생된 솔루션으로는 ▲파스트림 ▲아이리스DB ▲인피니플럭스 등을 들 수 있고, 로그처리시스템에서 발전된 솔루션으로는 ▲스플렁크 ▲테라스트림 바스 ▲로그프레소 ▲D2 등을 꼽을 수 있다.
<이하 상세 내용 컴퓨터월드 9월호 참조>