네트워크 DPI 솔루션이나 EDR 등 엔드포인트 솔루션을 통해 의심스러운 바이너리 해시, IP 주소, 도메인을 수집한 경우, 바이러스토탈 API와 연계하여 악성 여부를 진단할 수 있습니다.
API 키 발급
바이러스토탈에 가입한 후 커뮤니티 프로필에서 아래와 같이 API 키를 확인할 수 있습니다.

모든 API는 JSON 형태로 응답을 반환하며, 아래의 속성을 포함하고 있습니다:
- response_code: 1 (분석 결과 있음), 0 (분석 결과 없음), -2 (분석 진행중)
- verbose_msg: 응답코드와 관련된 메시지
아래의 예시들은 임의로 진단결과가 존재하는 레코드를 만들어서 REST API를 호출하고 있으나, 예제 쿼리들을 스트림 쿼리로 설정하면 의심되는 정보를 실시간으로 바이러스토탈과 연동하여 조회할 수 있습니다. 다만, 커뮤니티 계정인 경우 바이러스토탈 서비스에서 분당 호출 횟수를 제한합니다.
예제 쿼리의 VIRUSTOTAL_API_KEY 부분은 발급받은 API 키로 교체하셔야 실행됩니다.
파일 해시 조회
json "{}"
| eval md5 = "7657fcb7d772448a6d8504e4b20168b8"
| eval url = concat("https://www.virustotal.com/vtapi/v2/file/report?apikey=VIRUSTOTAL_API_KEY&resource=", md5)
| wget
| parsejson
| parsemap field=line
| fields scan_id, total, positives, md5, sha256
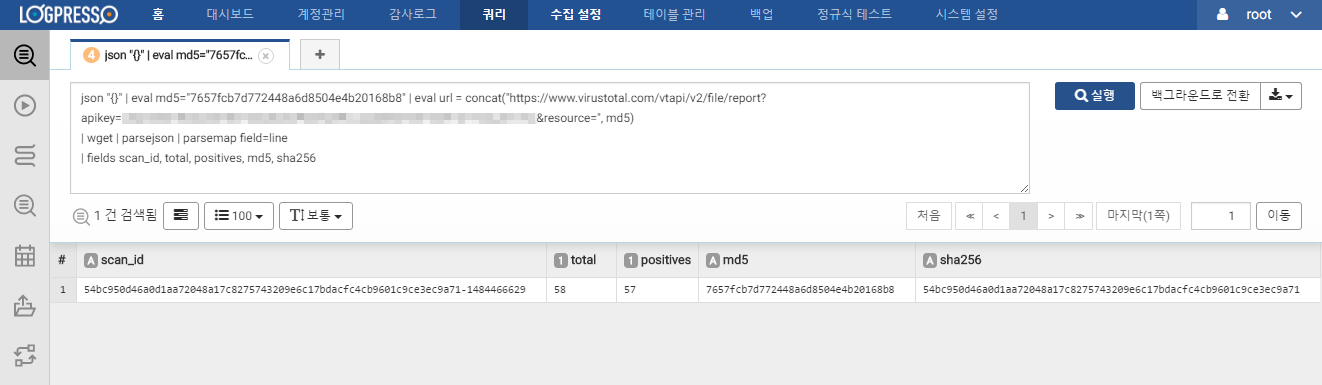
호출하는 URL의 resource 매개변수는 MD5, SHA1, SHA256 해시 중 하나를 사용할 수 있습니다. total은 전체 진단 수, positives는 악성으로 탐지된 수를 의미하므로, positives / total 비율이 높은 경우 악성코드로 진단할 수 있습니다.
IP 주소 조회
json "{}"
| eval ip = "90.156.201.27"
| eval url = concat("https://www.virustotal.com/vtapi/v2/ip-address/report?apikey=VIRUSTOTAL_API_KEY&ip=", ip)
| wget
| parsejson overlay=t
| parsemap field=line
| explode detected_urls
| parsemap overlay=t field=detected_urls
| fields ip, response_code, url, positives, total, scan_date
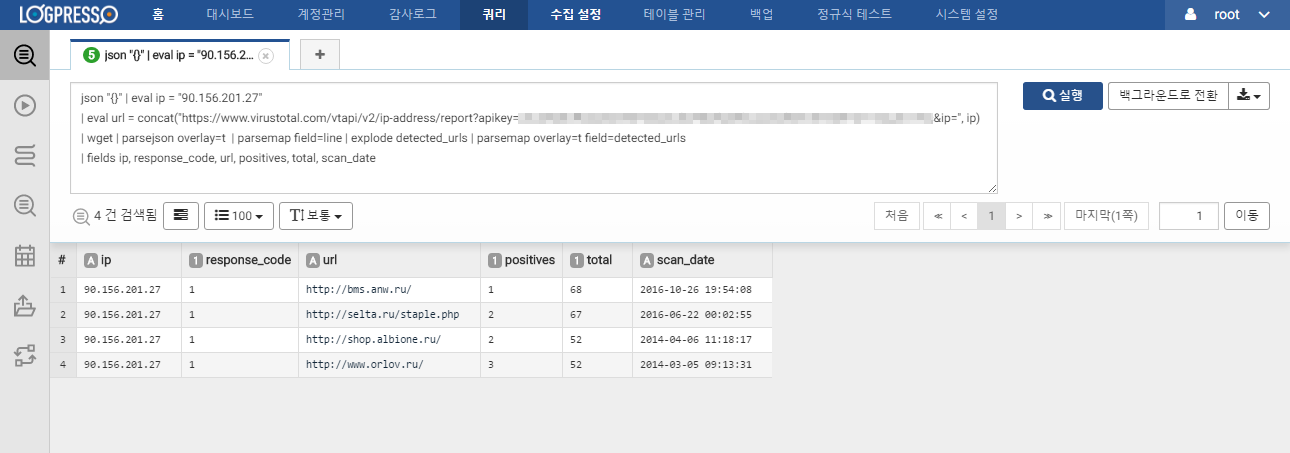
IP 분석 결과는 위의 스크린샷처럼 주어진 IP와 연관된 악성 URL 정보를 포함합니다.
도메인 조회
json "{}"
| eval domain = "027.ru"
| eval url = concat("https://www.virustotal.com/vtapi/v2/domain/report?apikey=VIRUSTOTAL_API_KEY&domain=", domain)
| wget
| parsejson overlay=t
| parsemap field=line
| explode detected_urls
| parsemap overlay=t field=detected_urls
| fields domain, response_code, categories, url, positives, total, scan_date
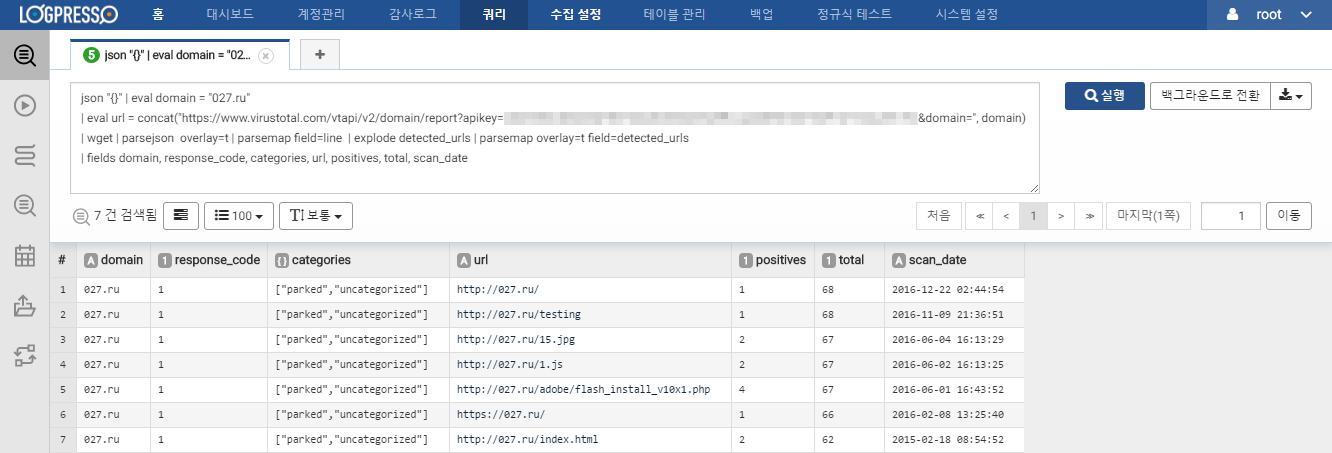
도메인 분석 결과는 위의 스크린샷처럼 주어진 도메인과 연관된 악성 URL 정보를 포함합니다.


