쿼리는 사용자와 데이터베이스를 매개하는 역할을 수행합니다. 응용프로그램을 개발할 때 파일 입출력을 직접 다루는 대신 데이터베이스를 사용하는 이유는 의도하는 데이터 처리 결과를 간단하게 얻을 수 있기 때문인데요. 쿼리를 사용하면 프로그램 코드를 작성하는 것에 비해 같은 작업을 훨씬 짧게 표현할 수 있습니다.
예를 들어 웹 로그에서 클라이언트 IP별 다운로드 트래픽 총량을 계산하려면 아래와 같은 과정을 거쳐야 합니다. 웹 로그는 아래와 같은 형식으로 기록됩니다.
110.70.47.162 - - [23/May/2020:13:24:22 +0900] "GET /static/images/favicon.png HTTP/1.1" 200 57692 "-" "Mozilla/5.0 (iPhone; CPU iPhone OS 13_4 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) CriOS/81.0.4044.124 Mobile/15E148 Safari/604.1" 849
- 웹 로그 파일을 연다.
- IP와 정수로 구성된 해시테이블을 초기화한다.
- 웹 로그 파일을 개행 문자로 분리해서 행 단위로 읽어들인다.
- 웹 로그에서 클라이언트 IP와 전송량에 해당되는 문자열을 추출한다.
- 전송량 문자열을 정수로 변환한다.
- 해시테이블에서 클라이언트 IP를 조회한다.
- 기존 누적값과 현재 전송량을 합산하여 클라이언트 IP와 전송량의 쌍을 다시 해시테이블에 넣는다.
- 파일 끝을 만나면 해시테이블의 모든 클라이언트 IP 키를 순회하면서 결과를 출력한다.
- 웹 로그 파일을 닫는다.
프로그래밍 언어에 따라 다르지만 파이썬으로는 몇 줄, 자바로는 수십 줄 정도 구현이 필요할 것이고, 클라이언트 IP가 엄청나게 많아서 메모리에 다 올릴 수 없는 상황은 고려하지 않고 있습니다.
만약 일반적인 데이터베이스 테이블에 웹 로그가 파싱되어 저장되어 있는 상태라면 일반적으로 SQL을 이용해서 간단하게 1줄로 쿼리할 수 있습니다.
weblog 테이블에 데이터가 정규화된 형태로 존재한다면 로그프레소 쿼리는 아래와 같이 표현합니다.
일반 데이터베이스는 테이블에 적재되지 않은 데이터를 처리하지 못하지만, 로그프레소는 아래와 같이 추출과 형 변환을 포함하여 모든 데이터 처리를 한 줄로 표현할 수 있습니다.
textfile access_log | rex field=line "^(?<client_ip>\S+).* (?<bytes>\S+)$" | eval bytes=long(bytes) | stats sum(bytes) by client_ip
쿼리 실행 단계
데이터베이스는 위와 같이 기술한 쿼리 문장을 실제 실행 가능한 코드로 변환해야 합니다. 이 과정은 크게 쿼리 파싱, 최적화, 실행으로 구분합니다.
쿼리 파싱

쿼리는 한 줄로 간단하게 표현하였지만 프로그램 코드를 직접 작성한 것과 동일하게 동작하려면 각 기능 단위가 사용자의 의도에 맞게 배치되어야 합니다. 데이터베이스는 이러한 기능 단위를 쿼리 연산자 (Query Operator) 라고 부릅니다. 각 쿼리 연산자는 레코드를 입력 받아서 고유의 데이터 처리를 수행한 후 출력하며, 다음 연산자는 이전 연산자의 출력을 입력으로 받아들입니다.
위의 그림에서 실행 흐름은 아래에서 위로 올라가는 방향으로 표현되어 있는데 이것이 약간 부자연스럽게 느껴질 수 있습니다. 하지만 조인 연산이 포함되는 경우에 하단이 늘어나면서 넓게 배치되고 결과는 하나로 모이게 되므로 트리 형태로 표현하는 것이 유리하고, 그에 맞춰서 실행 흐름은 아래에서 위로 표시하는 것입니다.
최적화
데이터베이스는 쿼리를 파싱하여 트리 형태로 만들고 난 후에 이를 논리적, 물리적으로 최적화하는 과정을 수행합니다. 예를 들어, 위의 경우에 집계를 수행하므로 테이블 혹은 파일의 레코드 순서는 중요하지 않습니다. 따라서 병렬화된 테이블 스캔 혹은 파일 스캔으로 변환할 수 있습니다. 이 외에도 타입 추론, 비용 계산, 조인 순서, 필터링 위치 결정은 쿼리 최적화에서 중요한 주제인데 이는 나중에 다시 다루도록 하겠습니다.

실행
최적화를 거치고 나면 최종적으로 쿼리 실행 계획 (Query Plan) 이 완성됩니다. 데이터베이스는 이 쿼리를 실행하는데 어느 정도의 CPU, 메모리, 디스크 자원을 사용할지 결정해야 합니다. 가장 단순하게는 프로그램을 직접 구현해서 실행하듯이 단일 프로세스가 쿼리를 실행할 수 있습니다.
프로세스 모델
PostgreSQL처럼 역사가 오래된 데이터베이스는 프로세스 모델 기반으로 동작합니다.
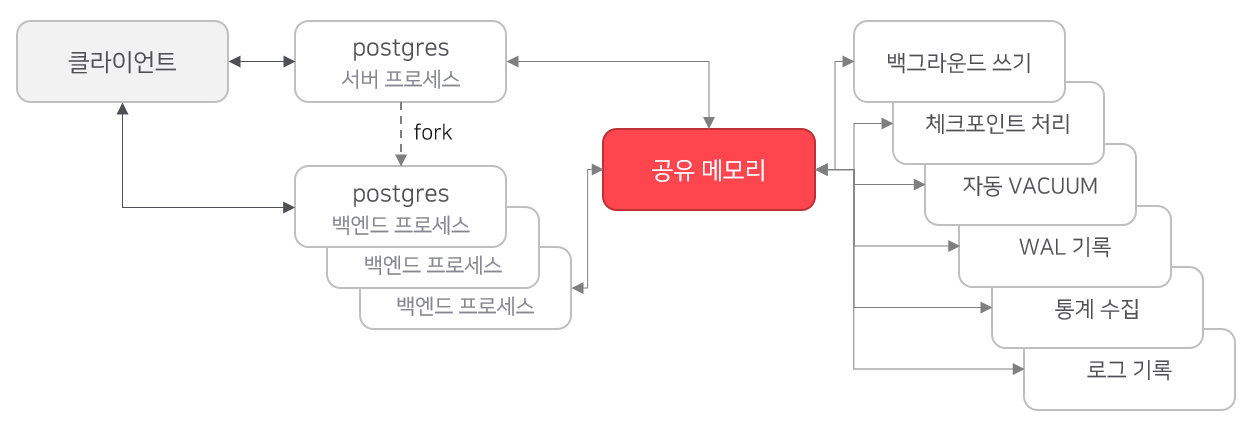
프로세스 모델은 클라이언트가 접속하면 새로운 프로세스를 생성해서 할당합니다. 유닉스 프로그래밍 스타일의 오랜 전통이기도 하지만, 공유 메모리를 기반으로 프로세스를 분리하는 이런 실행 모델은 프로그램 오류로 크래시가 발생하더라도 해당 프로세스만 영향을 받기 때문에 상대적으로 장애에 견고합니다. 프로세스가 재시작하더라도 디스크에서 다시 읽어들일 필요 없이 공유 메모리 영역이 그대로 유지되는 장점도 있습니다. IBM DB2, Oracle (11g 이하 버전) 데이터베이스는 이러한 아키텍처로 설계되어 있습니다.
그러나 프로세스를 fork 하는 방식은 상당히 무거운 편입니다. 프로세스 풀링을 통해 어느 정도 단점을 희석시키기는 하지만, 운영체제에 실행을 맡기므로 스케줄링을 세밀하게 관리하기 어렵고 CPU 캐시 활용도 비효율적입니다.
스레드 모델
로그프레소 쿼리 엔진은 스레드 모델 기반으로 동작합니다.
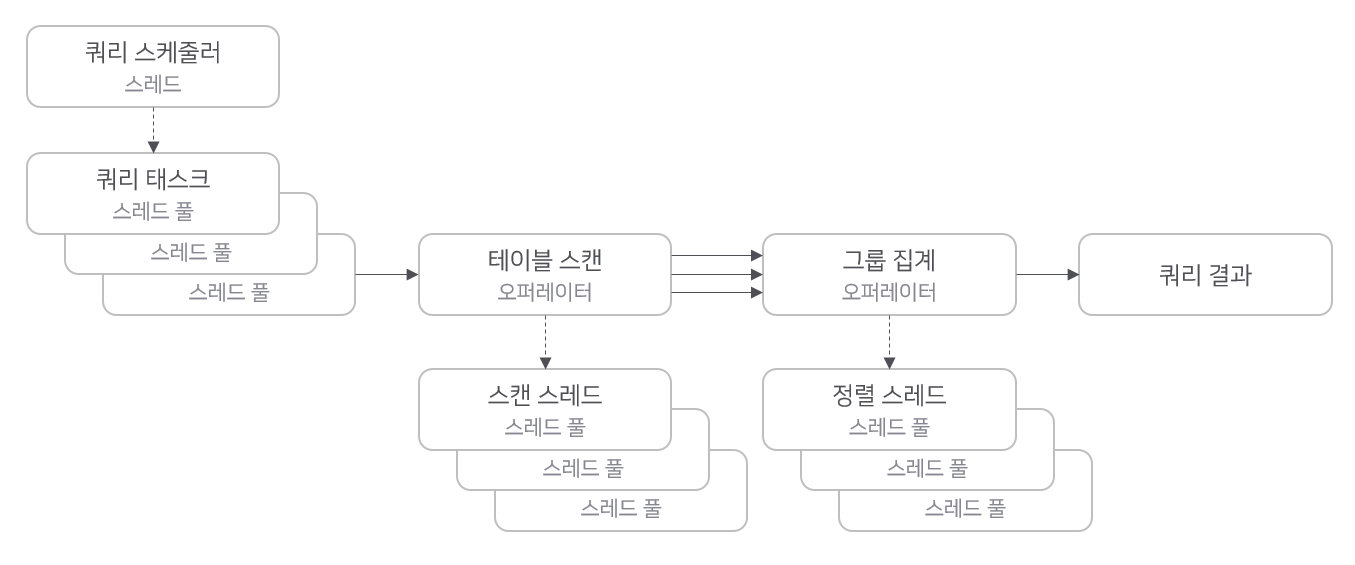
로그프레소는 쿼리마다 하나의 쿼리 스케줄러 스레드를 실행합니다. 쿼리 스케줄러는 쿼리 실행 계획에서 의존성이 해소된 실행 가능한 태스크를 선별하여 쿼리 태스크를 병렬적으로 실행합니다. 스캔이나 정렬과 같이 실행 성능에 큰 영향을 미치는 요소는 별도의 스레드 풀이 할당되어 있어서, CPU를 최대한 활용하여 빅데이터 쿼리를 실행합니다. 로그프레소 쿼리 엔진은 푸시 모델로 구성되어 있기 때문에, 스캔 스레드의 병렬화가 전체 쿼리의 수행 성능을 좌우합니다. 메모리에 캐시된 페이지를 처리하는 경우 이러한 병렬화는 수 배 이상의 성능 차이를 낼 수 있습니다.
다음 편에서는 Pull 모델과 Push 모델의 장단점을 알아보도록 하겠습니다.


