액티브 디렉터리는 중앙 집중적으로 인증을 처리하며 그룹 정책을 관리하기 때문에 계정, 호스트 등 많은 양의 정보가 내재되어 있습니다. 온프레미스 환경에서 액티브 디렉터리의 정보를 통합하려면 LDAP 프로토콜을 사용해야 합니다.
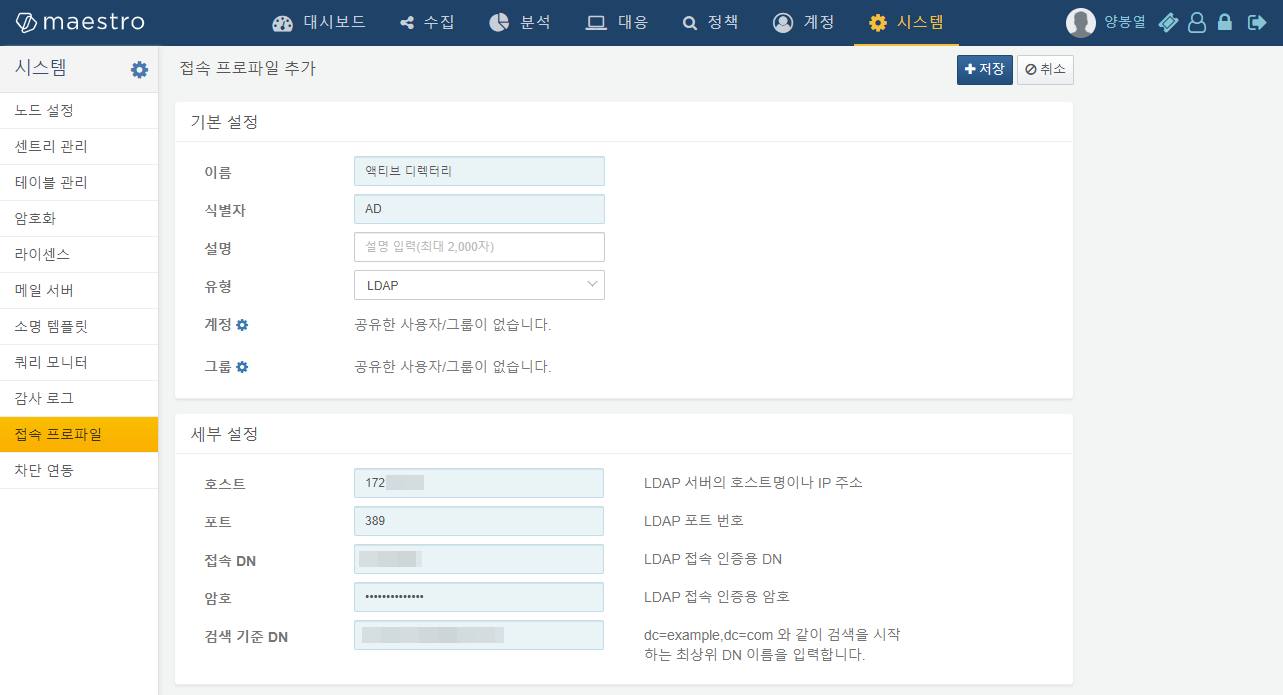
로그프레소에서 액티브 디렉터리를 연동하려면 먼저 LDAP 프로파일을 등록해야 합니다.
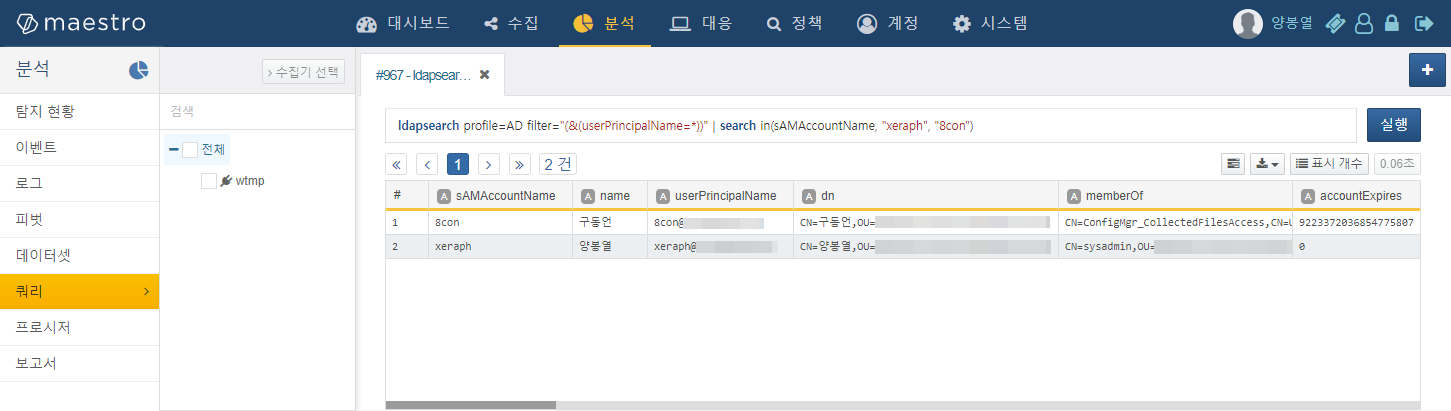
설정이 완료되면 아래와 같이 ldapsearch 쿼리와 LDAP 필터를 이용하여 액티브 디렉터리에 등록된 계정 목록을 조회할 수 있습니다:
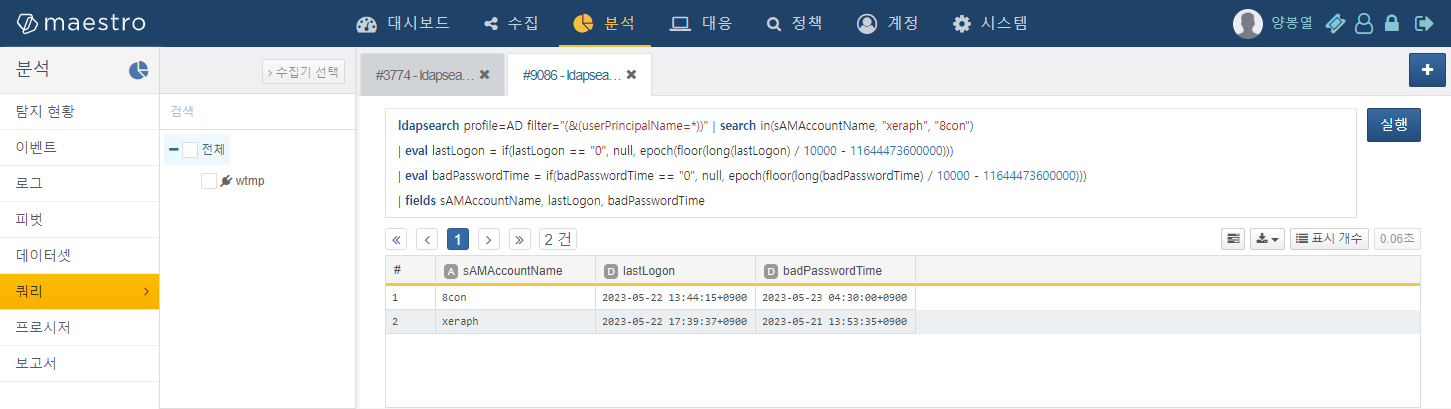
수십 가지의 계정 정보를 확인할 수 있습니다만, 타임스탬프는 윈도우 FileTime 형식이기 때문에 보기가 어렵습니다. FileTime은 아래와 같이 변환하여 볼 수 있습니다.
ldapsearch profile=AD filter="(&(userPrincipalName=*))"
| eval lastLogon = if(lastLogon == "0", null, epoch(floor(long(lastLogon) / 10000 - 11644473600000)))
| eval badPasswordTime = if(badPasswordTime == "0", null, epoch(floor(long(badPasswordTime) / 10000 - 11644473600000)))
| order sAMAccountName, lastLogon, badPasswordTime
액티브 디렉터리에 조인된 호스트 목록은 아래와 같이 확인할 수 있습니다.
ldapsearch profile=AD filter="(&(servicePrincipalName=*))"
| eval lastLogon = epoch(floor(long(lastLogon) / 10000 - 11644473600000))
| order cn, operatingSystem, operatingSystemVersion, lastLogon, whenCreated, whenChanged
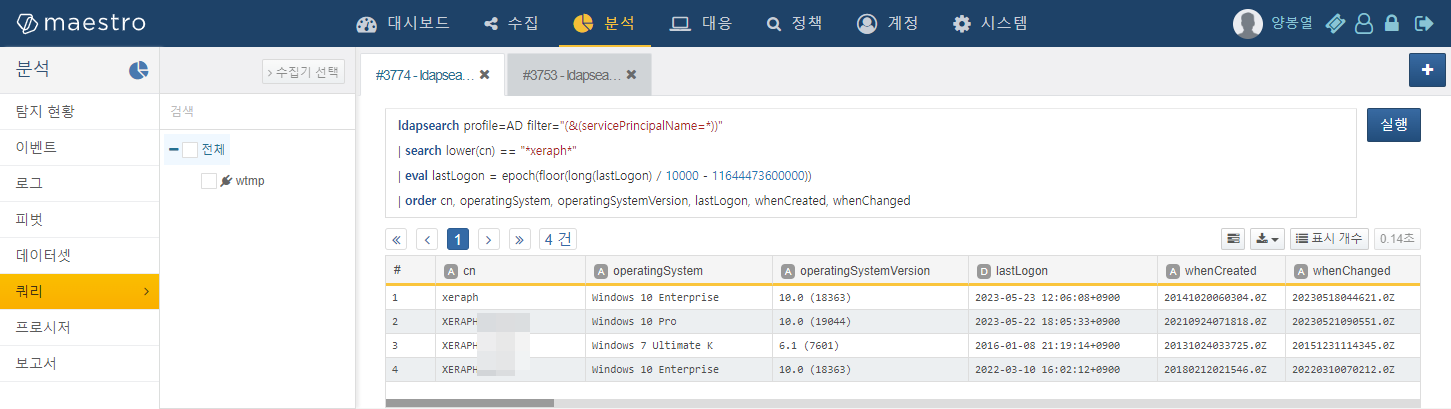
이렇게 로그프레소에 액티브 디렉터리 데이터를 통합하면 더 이상 사용되지 않는 계정이나 오래된 시스템을 주기적으로 식별하고 정리할 수 있으므로, 잠재적인 공격 표면을 줄이고 안정적으로 내부 IT 인프라를 관리할 수 있습니다.