NTFS는 윈도우즈 운영체제에서 지금까지 사용하고 있는 파일시스템입니다. 파일시스템은 물리적인 디스크 공간을 논리적인 디렉터리 계층과 파일 단위로 구조화하여 사용할 수 있도록 만들어줍니다.
스마트폰이 대중화된 이후 포렌식의 분석 대상이 개인정보를 집적하고 있는 모바일 기기로 많이 이동하고 있지만 여전히 윈도우즈 운영체제는 업무에서 핵심적인 생산성 도구입니다. 악성코드에 감염되거나 정보가 유출되었을 때 호스트에서 어떤 일이 발생했는지 알아내려면 NTFS 파일시스템에 대한 이해가 필수적입니다.
MFT: 마스터 파일 테이블
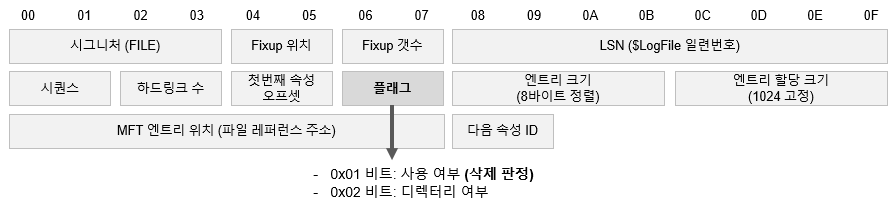
마스터 파일 테이블은 NTFS 파일시스템에 존재하는 모든 디렉터리와 파일에 대한 메타데이터를 유지합니다.
마스터 파일 테이블은 1024바이트 고정 길이 레코드로 구성되어 있으며, 파일 삭제 여부, 파일 크기, 디스크 할당 크기 등을 48바이트의 MFT 헤더에 담고 있습니다. 파일 이름, 접근 권한, 파일 생성/수정/접근 일시 등의 정보는 MFT 헤더 뒤에 이어지는 여러 가지의 속성 (Attribute) 에 포함됩니다.
분석에 가장 흔히 사용되는 속성은 $STANDARD_INFORMATION 과 $FILE_NAME 속성이며, 아래의 필드를 포함하고 있습니다.
- 파일 이름
- 디스크 할당 크기
- 실제 크기
- 파일 생성 일시
- 파일 수정 일시
- MFT 레코드 변경 일시
- 파일 액세스 일시
- 파일 권한
- 파일 속성 (숨김, 압축 등)
파일을 삭제하더라도 마스터 파일 테이블에서 즉시 삭제되지는 않으므로, 악성코드나 중요한 증적 파일이 삭제되더라도 MFT에서 삭제 흔적을 확인할 수 있습니다.
로그프레소 포렌식의 ntfs-mft 커맨드는 아래와 같은 필드 출력을 제공합니다.
- no: MFT 인덱스 번호
- file_path: 파일 경로
- file_name: 파일 이름
- file_size: 파일 크기
- alloc_size: 디스크 할당 크기
- in_use: 삭제 여부
- is_dir: 디렉터리 여부
- link_count: 하드링크 수
- created_at: 파일 생성일시 ($FILENAME 속성)
- modified_at: 파일 변경일시 ($FILENAME 속성)
- access_at: 파일 접근일시 ($FILENAME 속성)
- mft_modified_at: MFT 레코드 변경일시 ($FILENAME 속성)
- std_created_at: 파일 생성일시 ($STANDARD_INFORMATION 속성)
- std_modified_at: 파일 수정일시 ($STANDARD_INFORMATION 속성)
- std_mft_modified_at: MFT 레코드 변경일시 ($STANDARD_INFORMATION 속성)
- std_access_at: 파일 접근일시 ($STANDARD_INFORMATION 속성)
- is_readonly: 읽기전용 여부
- is_hidden: 숨김 여부
- is_system: 시스템 파일 여부
- is_archive: 보관 가능 여부
- is_device: 장치 여부
- is_normal: 일반 여부
- is_temp: 임시 파일 여부
- is_sparse: Sparse 여부
- is_reparse: Reparse 여부
- is_compressed: 압축 여부
- is_offline: 오프라인 여부
- is_indexed: 인덱스 여부
- is_encrypted: 암호화 여부
- lsn: $LogFile 시퀀스 번호
- seq: MFT 레코드 시퀀스 (레코드 재할당 시 증가)
- file_ref: 파일 참조 번호
- parent_file_ref: 디렉터리 파일 참조 번호
- parent_no: 디렉터리 MFT 인덱스 번호
USNJRNL: 저널링 로그
MFT에서 파일 삭제를 확인할 수는 있지만 사건을 조사할 때 또 하나 중요한 부분은 삭제 시점입니다. NTFS 파일시스템은 저널링을 지원하기 때문에, 파일 변경 이력을 $Extend 폴더의 $UsnJrnl 파일에 기록합니다.
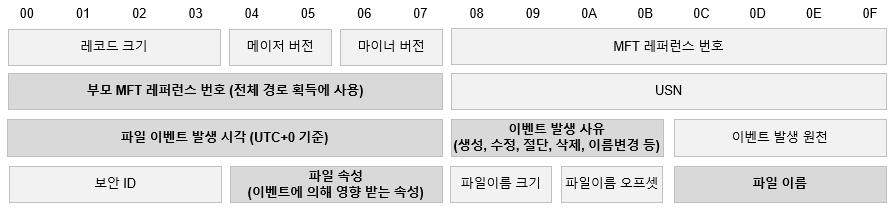
따라서 USNJRNL 파일을 분석하면 시스템에서 언제, 어떤 파일을 대상으로 어떤 작업을 수행했는지 파악할 수 있습니다.
ntfs-usnjrnl 커맨드는 아래와 같은 필드 출력을 제공합니다.
- _time: 파일 이벤트 시각
- file_name: 파일 이름
- file_no: MFT 인덱스 번호
- file_ref: 파일 참조 번호
- parent_file_no: 디렉터리 MFT 인덱스 번호
- parent_file_ref: 디렉터리 참조 번호
- reason: 파일 작업 목록
- usn: 레코드 오프셋 (Update Sequence Number)
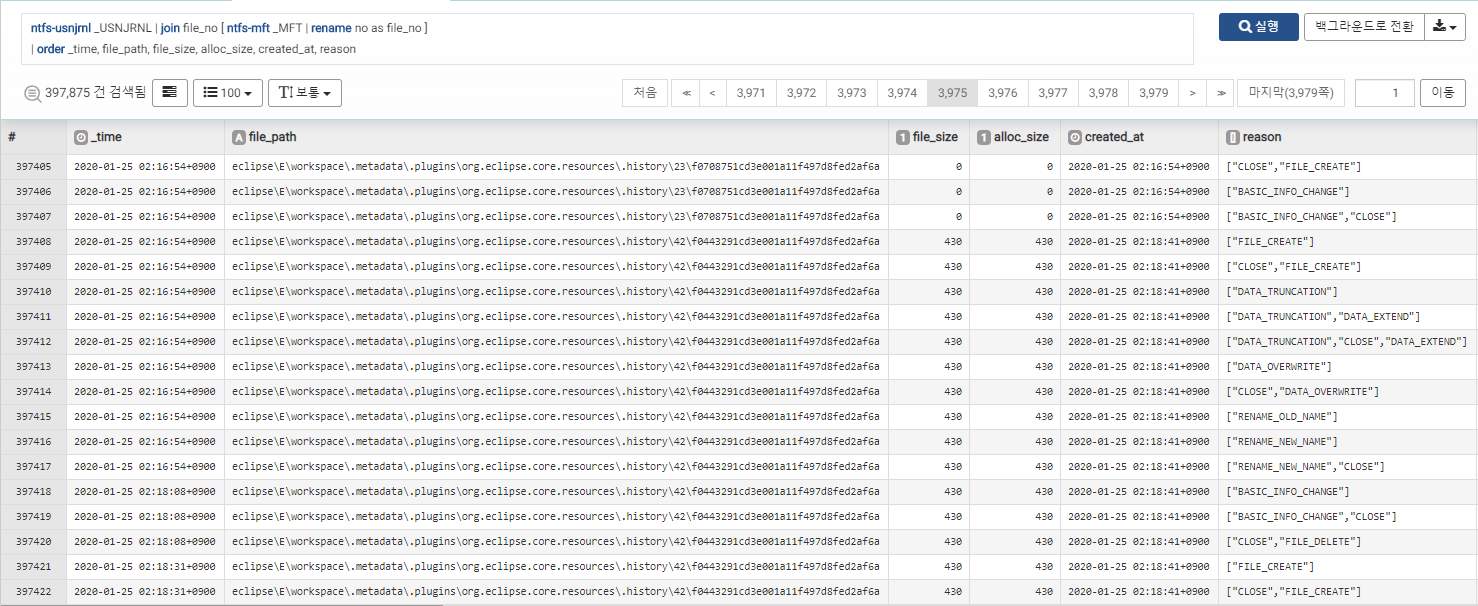
저널링 로그는 MFT를 번호로 참조하기 때문에, 아래와 같이 조인하여 완전한 파일 경로를 확보할 수 있습니다.
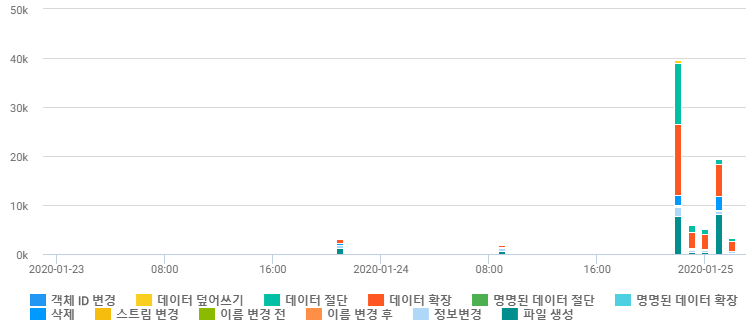
이러한 파일 변경 이력은 간단히 통계 처리하여 아래와 같이 타임라인을 시각화 할 수도 있습니다.
코드게이트 포렌식 문제 연습
로그프레소 포렌식 솔루션은 쿼리를 기반으로 다양한 포렌식 아티팩트를 연관 분석하는 강력한 기능을 지원합니다. 아래에서는 이전 코드게이트 2012 컨퍼런스에서 NTFS와 관련하여 출제된 문제를 어떻게 분석하는지 설명합니다.
In Energy corporate X which is located in Seoul, APT(Advanced Persistent Threat) was occurred. For 6 months, Attacker A has stolen critical information with an elaborate attack.
Attacker A exerted great effort to remove his all traces such as malicious file, prefetch, registry and event logs for the period of attacking, so it was hard for Energy Corporate X to find an attacking path.
However IU who is Forensic expert can find the traces of the malicious files Attacker A used by analyzing MFT (Master File Table).
What time malicious file was created? The time is based on Korea Standard Time (UTC +09:00)
- Codegate 2012 Forensic 400 문제 파일
400점 문제이지만 풀이 방법을 알면 간단하게 접근할 수 있습니다. 문제 지문에서는 MFT를 분석 대상으로 제시하고 있고, 공격자가 프리페치를 삭제하려고 시도하였다고 언급하여 실행 파일을 암시하고 있습니다. 문제의 목표는 악성코드 생성일시를 찾는 것입니다.

간단한 확장자 검색으로 휴지통에 있는 r32.exe 파일이 2012-02-23 02:39:18 KST에 생성되었고 파일 크기가 82944 바이트라는 사실을 확인할 수 있습니다.


