사이버 보안 분야의 머신러닝 모델링은 네트워크 프로토콜, 로그 기록 방식, 공격 기법, 취약점 등에 대해 종합적으로 이해하고 있어야 하기 때문에 처음 시작하는데 많은 어려움이 있습니다.
이번 글에서는 웹 로그를 대상으로 인터넷 봇 트래픽을 분류하는 모델을 만드는 과정을 통해 머신러닝 모델링 방법을 설명하려고 합니다. 인터넷 봇은 인터넷 익스플로러, 크롬과 같은 웹 브라우저가 아니라 자동화된 방식으로 웹사이트에 접속하는 프로그램을 의미합니다.
로그프레소에서는 실제로 따라할 수 있도록 로그프레소 스토어의 웹 로그를 익명화한 데이터를 제공합니다. opendata@logpresso.com 으로 연락주시면 데이터를 재배포하지 않으며 연구 목적으로만 사용하는데 동의하신 경우에 한해 데이터를 전달해드립니다. IP 주소를 익명화하는 대신, 접속 IP의 특성을 확인할 수 있도록 AI 스페라의 크리미널 IP 평판 정보 약 1만 건을 포함합니다.
이 웹 로그는 아래와 같은 필드를 포함하고 있습니다;
- 접속 시각, 로그 ID, 레이블, 익명화된 IP 식별번호, 크리미널 IP 평판, 국가, ASN, 처리 소요시간, HTTP 응답 상태, 다운로드 바이트, HTTP 메소드, 경로 및 쿼리스트링, 개행으로 구분된 HTTP 헤더 목록
봇 데이터 특성 확인
머신러닝 모델링에서 가장 먼저 해야할 일은 데이터의 특성 확인입니다. 사람이 구분하지 못하는 것은 기계도 구분하기 어렵습니다. 아래는 크롬 브라우저를 통해 접속한 경우 기록되는 HTTP 헤더입니다:
Host: logpresso.store
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36
Connection: Keep-Alive
Accept-Language: ko-KR,ko;q=0.9,en-US;q=0.8,en;q=0.7
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Referer: https://<masked>
Accept-Encoding: gzip, deflate, br
sec-ch-ua: "Chromium";v="104", " Not A;Brand";v="99", "Google Chrome";v="104"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "Windows"
upgrade-insecure-requests: 1
sec-fetch-site: cross-site
sec-fetch-mode: navigate
sec-fetch-user: ?1
sec-fetch-dest: document
content-length: 0
아래는 아이폰 사파리 브라우저에서 접속한 경우 기록되는 HTTP 헤더입니다:
Host: logpresso.store
User-Agent: Mozilla/5.0 (iPhone; CPU iPhone OS 16_0_2 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.0 Mobile/15E148 Safari/604.1
Connection: Keep-Alive
Accept-Language: ko-KR,ko;q=0.9
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Referer: https://www.logpresso.com/
Accept-Encoding: gzip, deflate, br
content-length: 0
아래는 masscan 봇이 접속한 경우 기록되는 HTTP 헤더입니다:
User-Agent: masscan/1.0 (https://github.com/robertdavidgraham/masscan)
Accept: */*
content-length: 0
아래는 zgrab 봇이 접속한 경우 기록되는 HTTP 헤더입니다:
Host: 3.39.215.159
User-Agent: Mozilla/5.0 zgrab/0.x
Accept: */*
Accept-Encoding: gzip
content-length: 0
아래는 Censys 봇이 접속한 경우 기록되는 HTTP 헤더입니다:
Host: 3.39.215.159
User-Agent: Mozilla/5.0 (compatible; CensysInspect/1.1; +https://about.censys.io/)
Accept-Encoding: gzip
Connection: close
content-length: 0
아래는 실제 공격의 HTTP 헤더입니다:
Host: 3.39.215.159
Content-Length: 20
Accept-Encoding: gzip, deflate
Accept: */*
User-agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36
Connection: keep-alive
Content-Type: application/x-www-form-urlencoded
몇 개 밖에 안 되는 샘플이지만 어느 정도 경향성이 눈에 보일 것입니다. 주목할 수 있는 봇 HTTP 트래픽의 특징은 아래와 같습니다:
- 전반적으로 HTTP 헤더의 수가 적은 경향이 있다.
- Host 헤더에 IP 주소가 사용되거나 존재하지 않는다.
- Accept 헤더는
*/*으로 모든 유형의 응답을 수락한다. - User-Agent 헤더 값은 마치 크롬 브라우저 같지만 브라우저 버전이 매우 낮다.
- Accept-Encoding 헤더는
br(Brotli) 같은 최신의 압축 유형을 지원하지 않는다. - Accept-Language 헤더가 없거나 quality factor 없이 단순하다.
- Referer 헤더가 존재하지 않는다.
왜 이러한 특징이 나타날까요? 봇은 자동화된 프로그램이므로 사용자 편의와 관련된 헤더가 없습니다. 인터넷을 광범위하게 스캔하며 활동하는 봇들은 특정 사이트를 목표로 하는 것이 아니기 때문에 도메인 정보가 없고 IP 주소 범위를 순차적으로 접속합니다. 반대로 말하면, 우리가 지금 만들고 있는 모델은 APT (Advanced Persistent Threat) 공격 탐지에는 적합하지 않다는 의미입니다. 단 하나의 모델이 모든 유형의 공격을 효과적으로 탐지하기는 어려우므로, 목적에 따라 모델을 조합할 필요가 있습니다.
한편, 2차적으로 파생되는 특성들도 존재합니다. IP 주소는 구간별로 ASN에 할당되는데, 샘플 데이터를 ASN (Autonomous System Number) 단위로 집계해보면 명확한 특성을 확인할 수 있습니다.
jsonfile masked_labeled_store_access.json
| pivot count rows asn cols label
| search in(asn, "*Korea Telecom*", "*OVH*", "*Free SAS*")
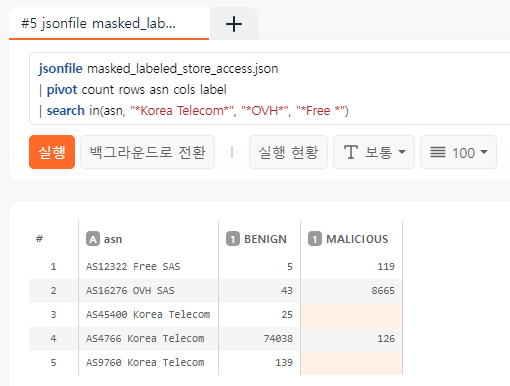
ASN에 따라 상당히 치우친 결과를 볼 수 있는데 이는 가입자망에서 직접 봇을 돌리는 것보다 클라우드나 호스팅 서비스에서 봇을 돌리는게 추적을 회피하는데 훨씬 유리하기 때문입니다. 그래서 경험이 많은 보안팀은 IP 대역만 봐도 직감적으로 정탐을 구분할 수 있습니다. 일반적인 고객이 굳이 클라우드나 호스팅 서비스를 통해 웹 서비스에 접속할 이유가 없습니다.
같은 맥락에서, 외부 인텔리전스를 활용하여 특정 IP 주소가 VPN IP 주소인지, 프록시 IP인지, TOR 노드 IP인지 구분할 수 있다면 정오탐을 판단하는데 상당한 도움이 될 것입니다. 아래는 샘플 데이터의 IP에 대해 AI 스페라에서 크리미널 IP 서비스의 평판 정보를 조회하여 생성한 자료입니다.
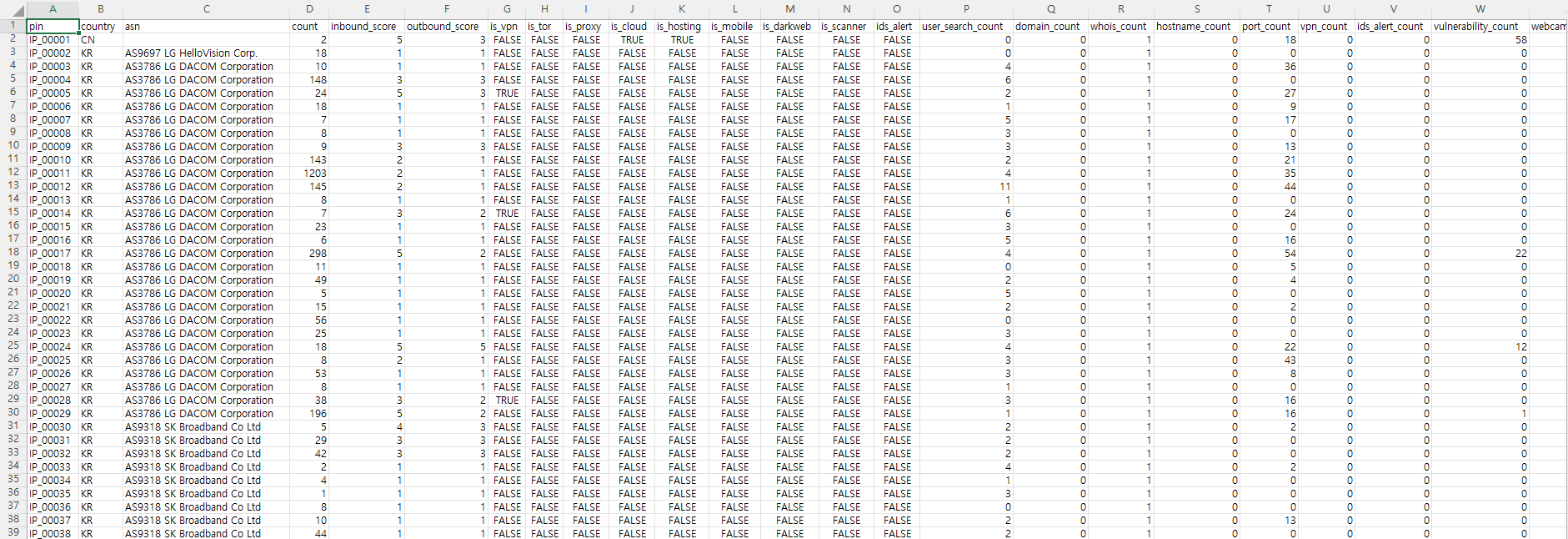
하지만 현실적으로 모든 접속 IP 주소에 대해 매번 평판을 조회하기는 어려우므로, 이 정보는 라벨링에만 사용할 것입니다.
masked_labeled_store_access.json 파일은 미리 라벨링이 되어있지만, 모델러가 처음 맞닥뜨리는 가장 어려운 문제는 어떻게 대량의 학습용 데이터를 라벨링할 것인가 하는 부분입니다. 데이터에 라벨링이 되어있지 않다면 어떻게 해야할까요?
휴리스틱을 이용한 공격 로그 라벨링
로그프레소는 강력한 쿼리 기능을 제공하므로 휴리스틱 룰을 적용하여 명백한 공격 로그와, 정상 로그를 나눠볼 수 있습니다. 예를 들면, 스캐너 봇은 아래와 같이 대량의 HTTP 404 오류를 유발합니다.
jsonfile masked_labeled_store_access.json
| search pin == "IP_09686"
| fields _time, log_id, pin, label, reputation, country, asn, method, uri, path, query, params, status, duration
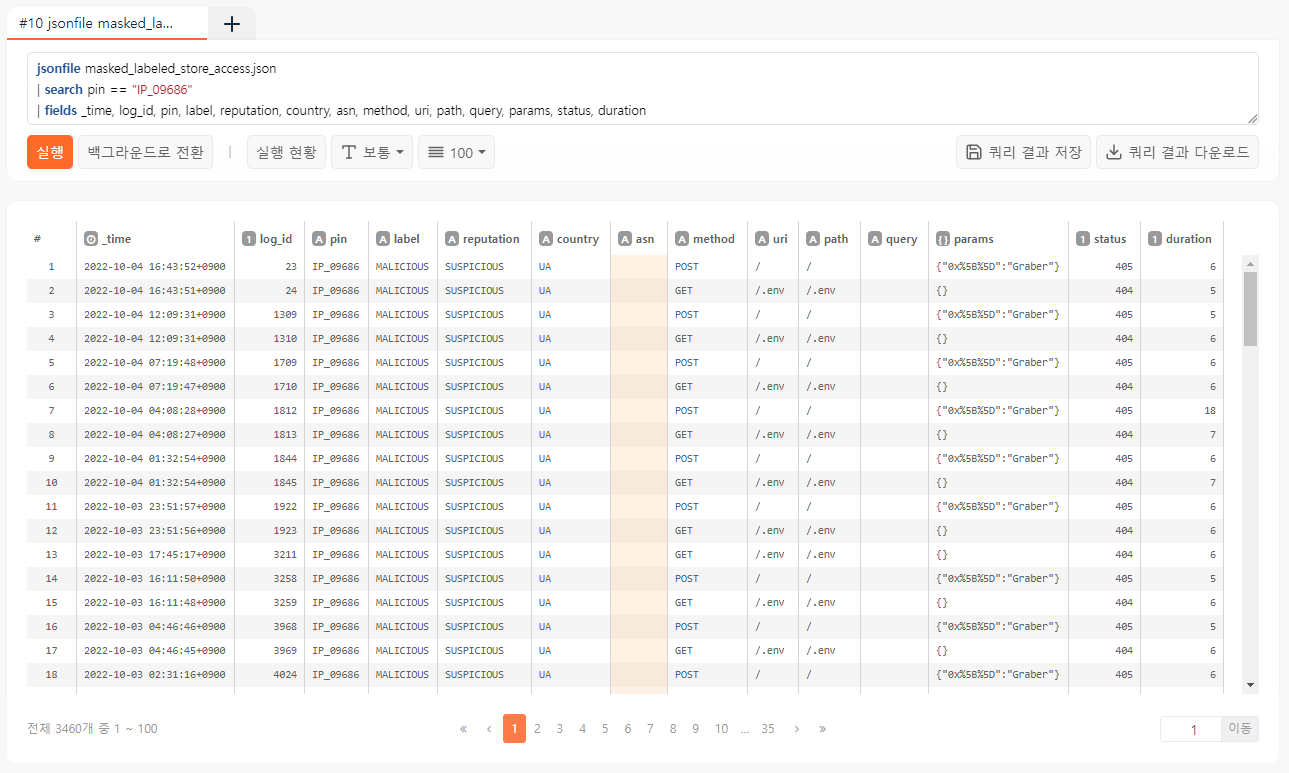
물론 정상적인 검색엔진의 경우에도 존재하지 않는 sitemap.xml 이나 favicon.ico 를 조회하려고 시도할 수 있으므로, 아래와 같이 404가 발생한 경로명들을 추출해보고 허용되는 접속 오류는 일부 수작업으로 걸러내도록 합니다.
jsonfile masked_labeled_store_access.json
| search status == 404
| stats count by path
| eval len = len(path)
| sort len
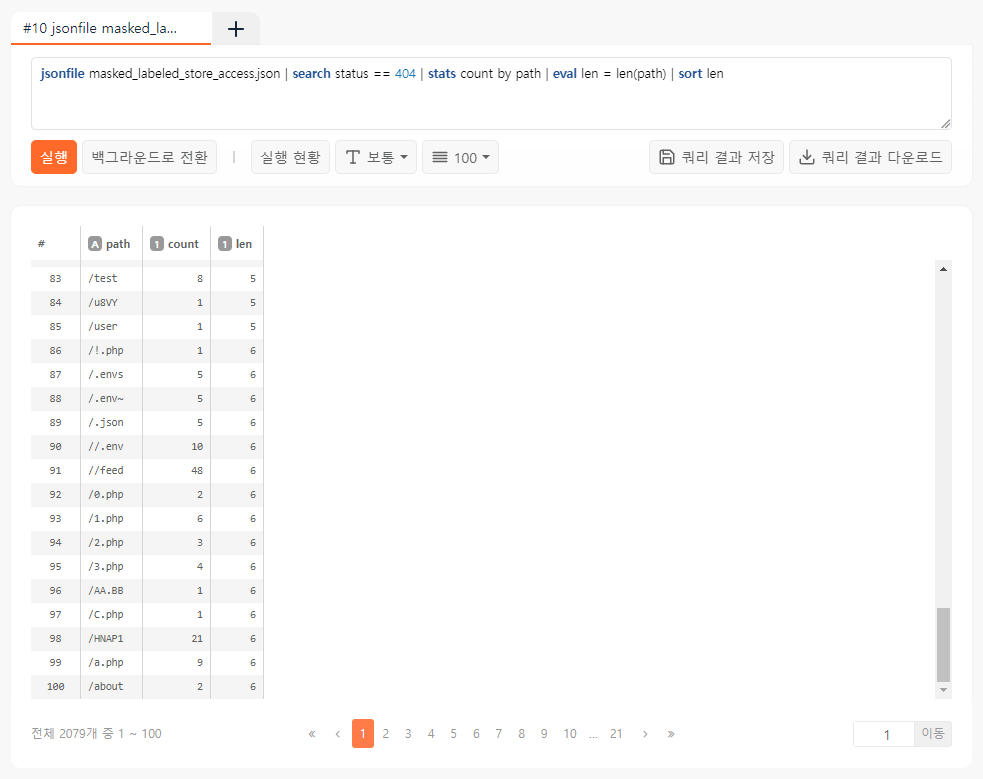
약 2000건 이상의 공격 경로들을 확인할 수 있습니다. 단, 일부 마스킹 관련된 오류가 있기도 하고, 앞서 언급한 것처럼 정상적인 404 접속 시도도 존재하므로 관련 없는 경로들은 제외해야 합니다.
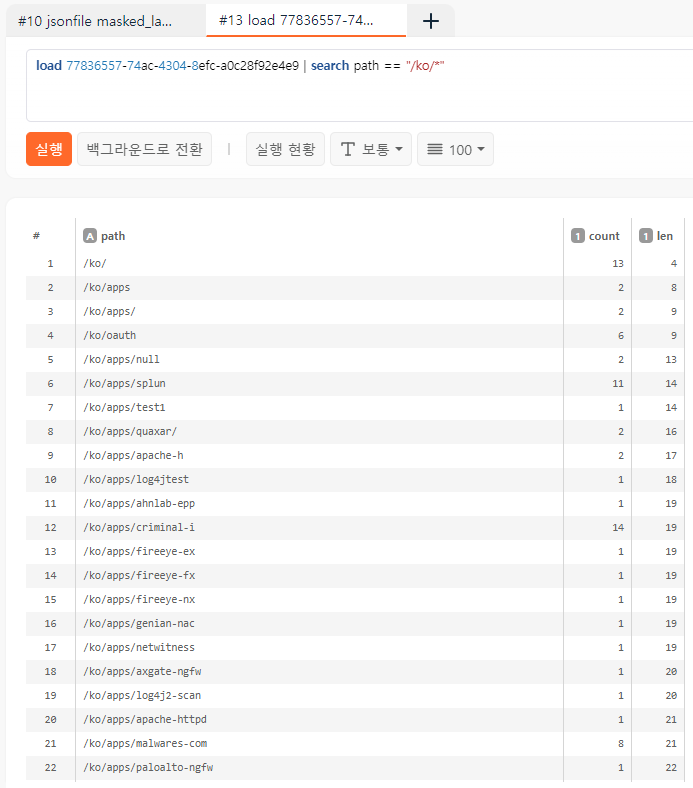
load 77836557-74ac-4304-8efc-a0c28f92e4e9
| search not(in(path, "/timezone", "/ko/oauth", "/ko/login", "/ko/apps*", "/en/apps*", "/apps*", "/en/packages/*", "/ko/packages/*", "", "/", "//", "/en", "/ko", "/ip", "/ko/", "/robots.txt", "/sitemap.txt", "//sitemap.xml", "/sitemap.xml.gz", "/sitemap_index.xml", "/apple-touch-icon.png", "/apple-touch-icon-precomposed.png"))
이 쿼리 결과를 저장해두고 아래와 같이 다시 불러와서 조인시키면 명백한 공격 로그를 식별할 수 있습니다. 불러오기 메뉴에서 저장된 쿼리 결과를 클릭하면 guid를 확인할 수 있습니다.
jsonfile masked_labeled_store_access.json
| join path [ load ba890e78-af76-4c4f-a658-185c68513681 | fields path ]
| fields _time, log_id, pin, label, reputation, country, asn, method, uri, path, query, params, status, duration
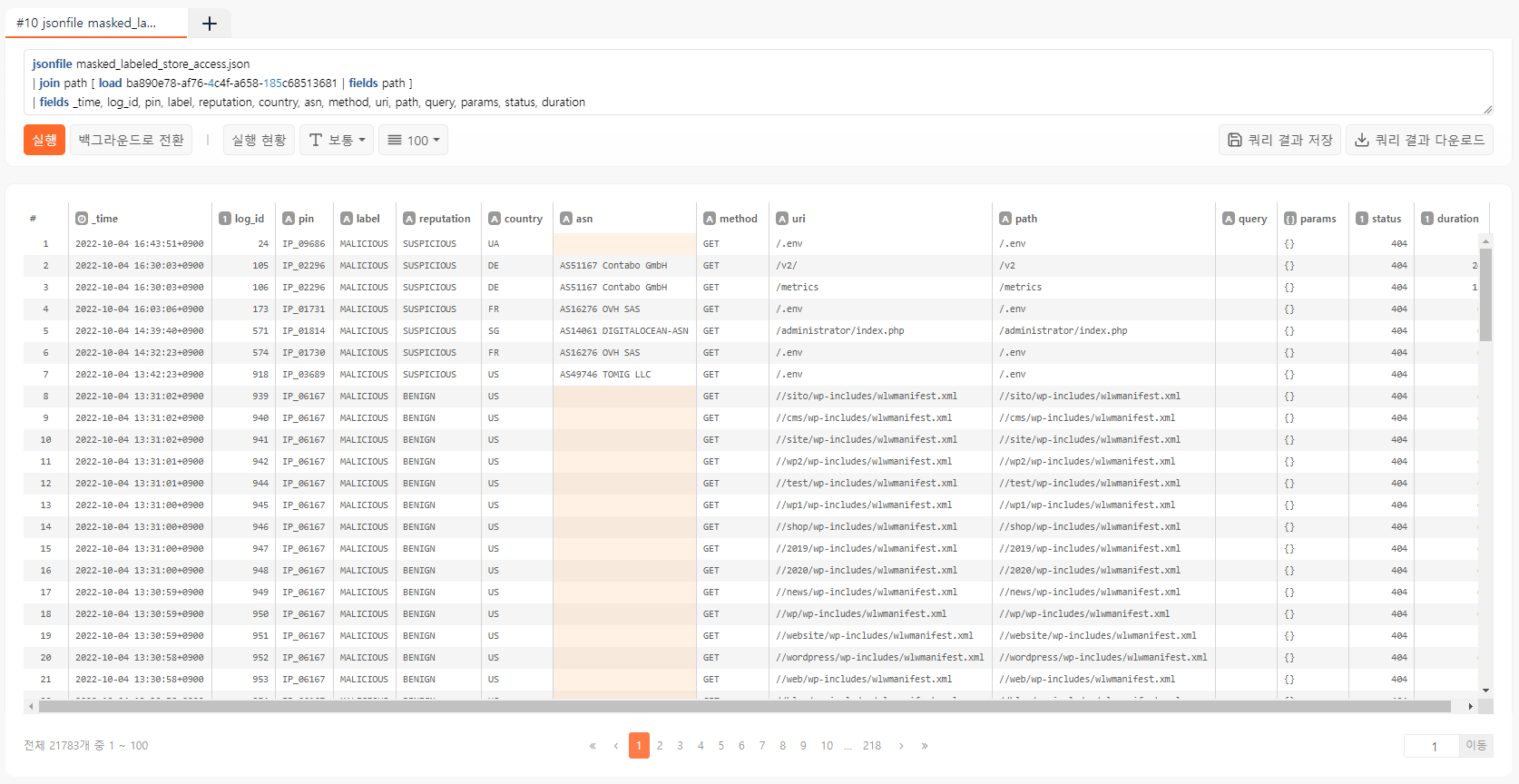
전체 29만건 중에서 2만건의 봇 접속 로그가 명확하게 식별되었습니다. 가장 흔하게 보이는 /wp-includes/wlwmanifest.xml 경로 접근은 워드프레스 취약점 공격입니다. 이 쿼리 결과는 이후에 정상 데이터와 합쳐서 학습 데이터로 만들 것입니다.
휴리스틱을 이용한 정상 로그 라벨링
봇이 아닌 일반적인 브라우저의 접속 로그만 확실하게 추려낼 수 있는 방법이 어떤게 있을까요? 봇들도 User-Agent 헤더로는 일반 브라우저인 것처럼 위장하기 때문에 에이전트 문자열을 이용하는 것은 적절하지 않습니다. 정상 로그는 상대적으로 훨씬 많으므로 여러가지 방법이 있을 수 있겠지만, 여기에서는 봇이 일반적으로 ETag 기반의 캐시 로직까지 따라하지는 않는다는 점을 이용하려고 합니다.
웹 브라우저가 이전 컨텐츠를 캐시하고 있어야만 if-none-match 헤더로 ETag를 전송할 수 있고, 그 값이 정확해야만 웹 서버가 304 Not Modified 응답하게 되니 일반적인 웹 브라우저일 가능성이 훨씬 높습니다.
jsonfile masked_labeled_store_access.json
| search status == 304
| fields _time, log_id, pin, label, reputation, country, asn, method, uri, headers
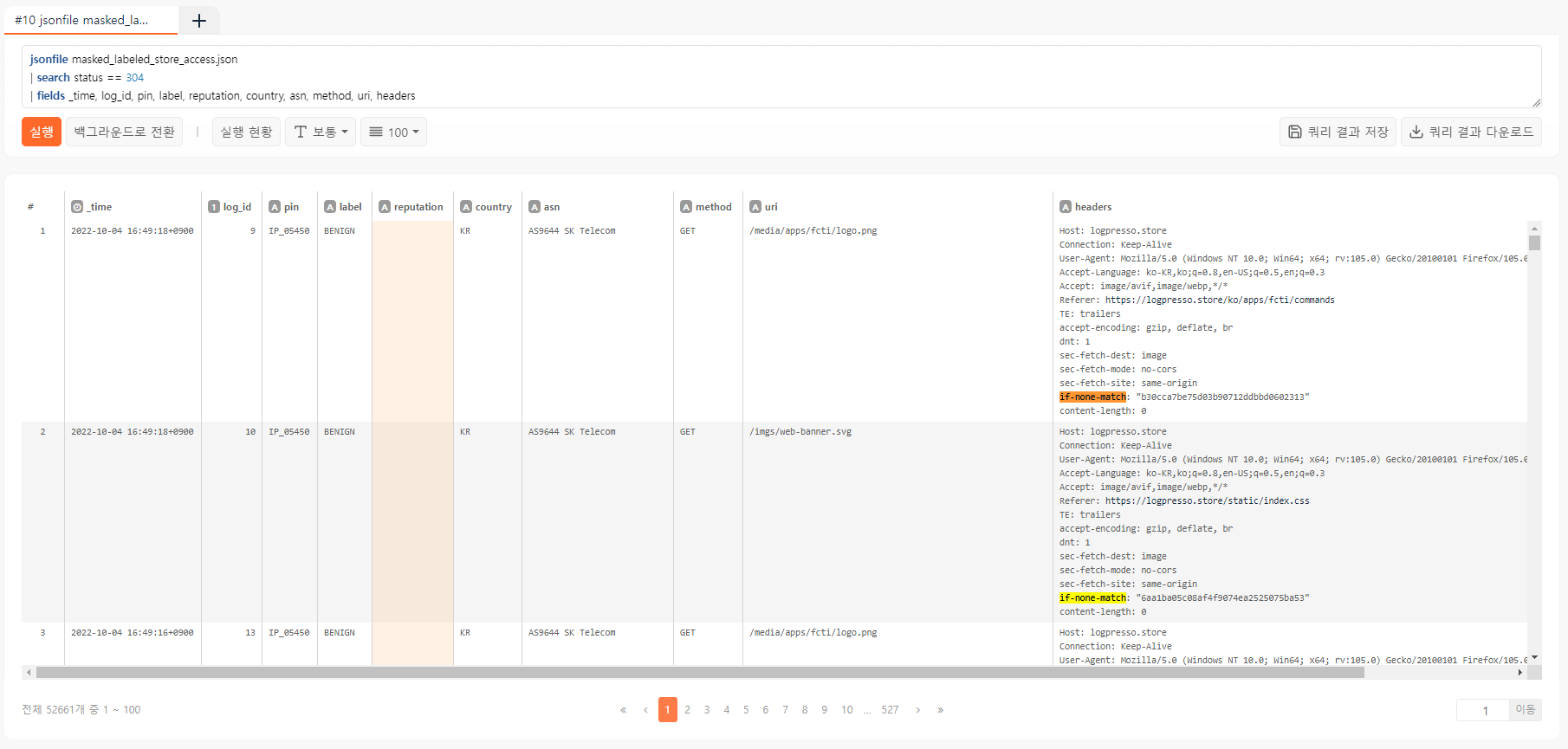
이제 정상으로 확신할 수 있는 약 5만건의 데이터가 확보되었습니다.
학습 데이터 생성
앞서 여러가지 봇 데이터 특성에 대하여 언급하였습니다. 이제 원본 데이터에서 특성(feature)을 추출해야 합니다. 정규표현식을 사용하면 간단히 원하는 헤더 항목을 추출할 수 있습니다. 정규식 앞부분의 (?i) 는 대소문자를 무시하라는 의미입니다.
jsonfile masked_labeled_store_access.json
| rex field=headers "(?i)user-agent: (?<user_agent>[^\n]+)"
| rex field=headers "(?i)accept-language: (?<accept_lang>[^\n]+)"
| rex field=headers "(?i)accept: (?<accept>[^\n]+)"
| rex field=headers "(?i)connection: (?<connection>[^\n]+)"
| rex field=headers "(?i)host: (?<host>[^\n]+)"
| rex field=headers "(?i)accept-encoding: (?<accept_encoding>[^\n]+)"
| rex field=headers "(?i)chrome/(?<chrome_ver>\d+)"
| rex field=headers "(?i)edg/(?<edge_ver>\d+)"
| rex field=headers "(?i)referer: (?<referer>[^\n]+)"
| rex field=headers "(?i)accept-encoding: (?<accept_encoding>[^\n]+)"
| rex field=headers "(?i)sec-fetch-site: (?<sec_fetch_site>[^\n]+)"
| fields _time, pin, user_agent, accept_lang, accept, connection, host, accept_encoding, chrome_ver, edge_ver, referer, accept_encoding, sec_fetch_site
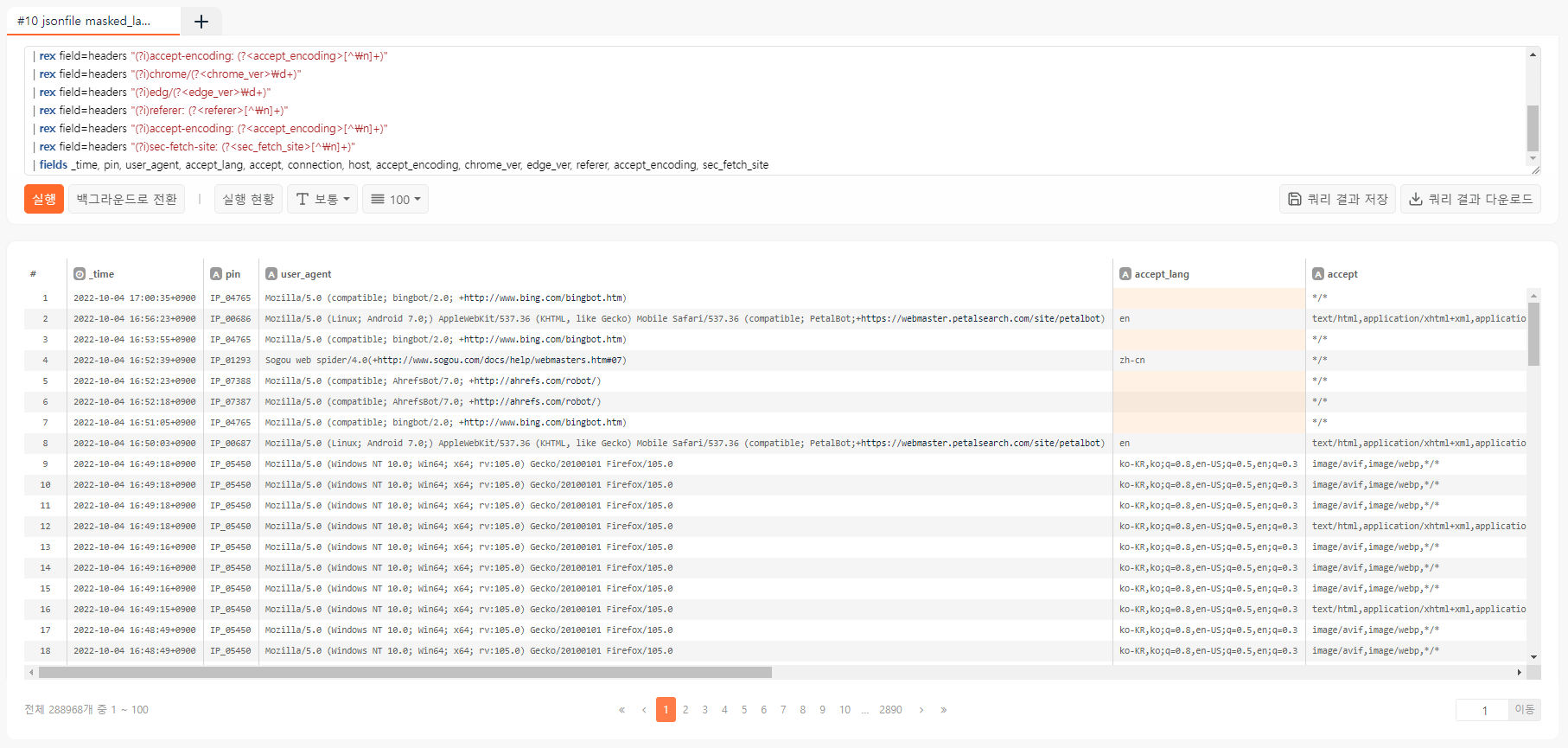
이 문자열 값들을 그대로 모델에 넣을 수도 있기는 하지만 나중에 학습되지 않은 범주형 (categorical) 값이 들어오면 분류 정확도가 떨어지기 때문에 좋은 결과를 기대하기 어렵습니다. 조금 더 전처리를 수행해봅시다:
jsonfile masked_labeled_store_access.json
| rex field=headers "(?i)user-agent: (?<user_agent>[^\n]+)"
| rex field=headers "(?i)accept-language: (?<accept_lang>[^\n]+)"
| rex field=headers "(?i)accept: (?<accept>[^\n]+)"
| rex field=headers "(?i)connection: (?<connection>[^\n]+)"
| rex field=headers "(?i)host: (?<host>[^\n]+)"
| rex field=headers "(?i)accept-encoding: (?<accept_encoding>[^\n]+)"
| rex field=headers "(?i)chrome/(?<chrome_ver>\d+)"
| rex field=headers "(?i)edg/(?<edge_ver>\d+)"
| rex field=headers "(?i)referer: (?<referer>[^\n]+)"
| rex field=headers "(?i)accept-encoding: (?<accept_encoding>[^\n]+)"
| rex field=headers "(?i)sec-fetch-site: (?<sec_fetch_site>[^\n]+)"
| eval accept_br = if(accept_encoding == "*br*", 1, 0)
| eval accept_sdch = if(accept_encoding == "*sdch*", 1, 0)
| eval chrome_ver = int(chrome_ver), edge_ver = int(edge_ver)
| eval python_client = if(lower(user_agent) == "*python*", 1, 0)
| eval go_client = if(lower(user_agent) == "*go-http-client*", 1, 0)
| eval java_client = if(lower(user_agent) == "*java*", 1, 0)
| eval fb_asn = if(asn == "*FACEBOOK*", 1, 0)
| eval google_asn = if(asn == "*GOOGLE*", 1, 0)
| eval ms_asn = if(asn == "*MICROSOFT*", 1, 0)
| eval huawei_asn = if(asn == "*HUAWEI CLOUDS*", 1, 0)
| eval yandex_asn = if(asn == "*YANDEX*", 1, 0)
| eval fb_client = if(in(user_agent, "*FBAN/FBIOS;FBDV*", "*facebookexternalhit*", "*cortex/1.0*", "*adreview*"), 1, 0)
| eval google_bot = if(in(user_agent, "*Googlebot-Image/*", "*Googlebot/*"), 1, 0)
| eval bing_bot = if(in(user_agent, "*bingbot/*"), 1, 0)
| eval petal_bot = if(in(user_agent, "*PetalBot*"), 1, 0)
| eval yandex_bot = if(in(user_agent, "*YandexBot/*"), 1, 0)
| eval accept_all = if(len(accept) == 3, 1, 0), keep_alive = if(lower(connection) == "keep-alive", 1, 0)
| eval has_referer = if(len(referer) > 0, 1, 0)
| eval has_sec_fetch_site = if(len(sec_fetch_site) > 0, 1, 0)
| eval header_count = len(split(headers, "\n")), host_header_ip = if(isnotnull(ip(host)), 1, 0)
| eval known_bot = if((google_bot > 0 and google_asn > 0) or (ms_asn > 0 and bing_bot > 0) or (fb_asn > 0 and fb_client > 0) or (huawei_asn > 0 and petal_bot > 0), 1, 0)
| fields _time, log_id, pin, header_count, has_sec_fetch_site, has_referer, accept_all, accept_br, accept_sdch, chrome_ver, python_client, go_client, java_client, fb_asn, google_asn, ms_asn, huawei_asn, yandex_asn, fb_client, google_bot, bing_bot, petal_bot, yandex_bot, known_bot
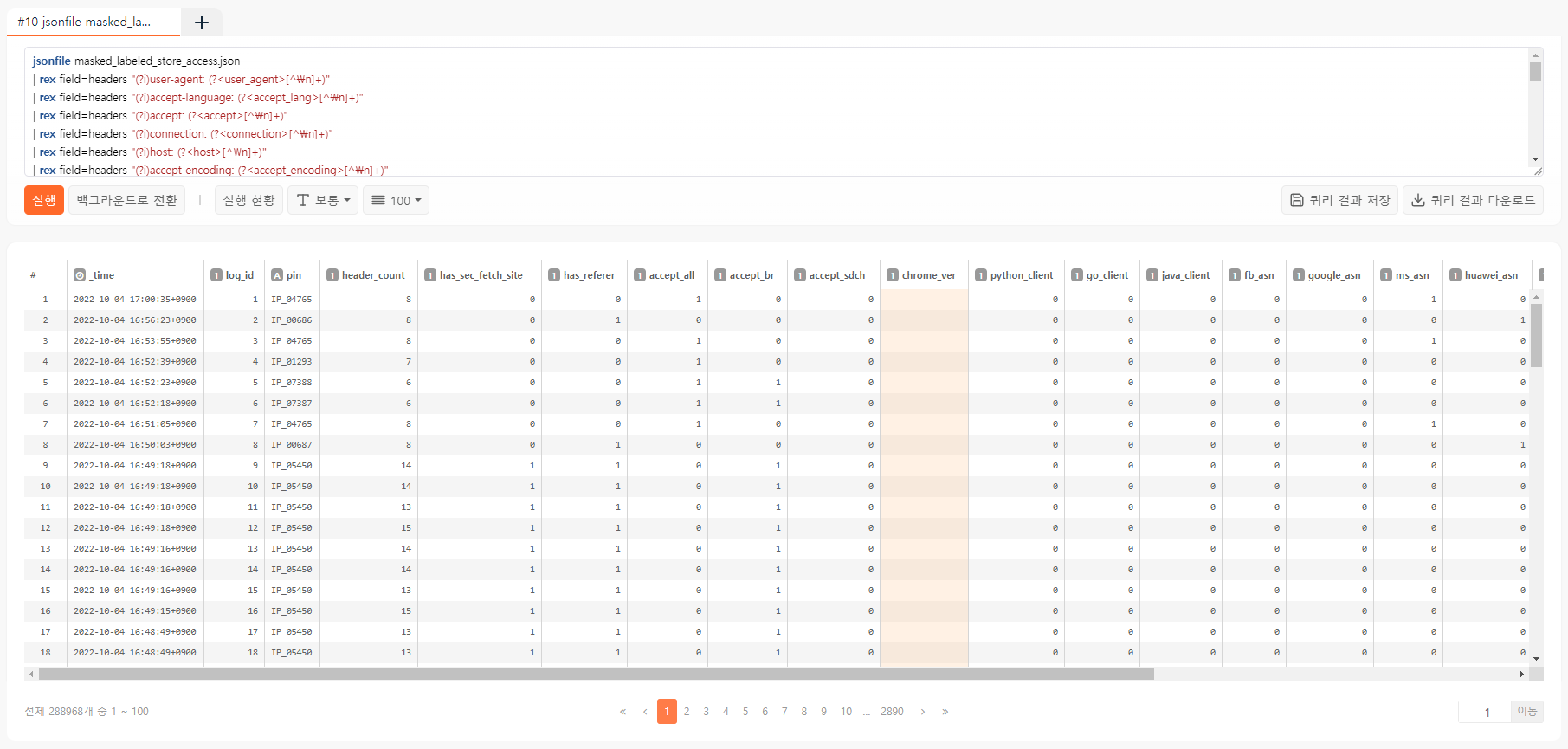
이제 수치형으로 깔끔하게 정리되었습니다. 각 특성의 의미는 아래와 같습니다:
- header_count: 헤더 수
- has_sec_fetch_site:
sec-fetch-site헤더 존재 여부 - has_referer:
referer헤더 존재 여부 - accept_all:
*/*여부 - accept_br:
br압축 가용 여부 - accept_sdch:
sdch압축 가용 여부 - chrome_ver: 크롬 버전
- python_client: Python 클라이언트 여부
- go_client: Go 클라이언트 여부
- java_client: 자바 클라이언트 여부
- fb_asn: 페이스북 ASN에서 접속
- google_asn: 구글 ASN에서 접속
- ms_asn: 마이크로소프트 ASN에서 접속
- huawei_asn: 화웨이 클라우드 ASN에서 접속
- yandex_asn: 얀덱스 ASN에서 접속
- fb_client: 페이스북 클라이언트 여부
- google_bot: User-Agent 헤더의 Google 봇 여부
- bing_bot: User-Agent 헤더의 Bing 봇 여부
- petal_bot: User-Agent 헤더의 Petal 봇 여부
- yandex_bot: User-Agent 헤더의 Yandex 봇 여부
- known_bot: 허용된 봇 여부. 위의 검색엔진 봇을 포괄하고 이후 IP 주소로 특정된 봇 허용
그러면 이제 이 모든 것을 합쳐서 라벨링된 학습 데이터를 만들 수 있습니다.
# 정상, 악성 라벨링된 데이터 병합
| jsonfile masked_labeled_store_access.json | search status == 304 | eval label = "BENIGN"
| union [
jsonfile masked_labeled_store_access.json
| join path [ load ba890e78-af76-4c4f-a658-185c68513681 | fields path ]
| eval label = "MALICIOUS"
]
| # 피처 추출 영역
| rex field=headers "(?i)user-agent: (?<user_agent>[^\n]+)"
| rex field=headers "(?i)accept-language: (?<accept_lang>[^\n]+)"
| rex field=headers "(?i)accept: (?<accept>[^\n]+)"
| rex field=headers "(?i)connection: (?<connection>[^\n]+)"
| rex field=headers "(?i)host: (?<host>[^\n]+)"
| rex field=headers "(?i)accept-encoding: (?<accept_encoding>[^\n]+)"
| rex field=headers "(?i)chrome/(?<chrome_ver>\d+)"
| rex field=headers "(?i)edg/(?<edge_ver>\d+)"
| rex field=headers "(?i)referer: (?<referer>[^\n]+)"
| rex field=headers "(?i)accept-encoding: (?<accept_encoding>[^\n]+)"
| rex field=headers "(?i)sec-fetch-site: (?<sec_fetch_site>[^\n]+)"
| eval accept_br = if(accept_encoding == "*br*", 1, 0)
| eval accept_sdch = if(accept_encoding == "*sdch*", 1, 0)
| eval chrome_ver = int(chrome_ver), edge_ver = int(edge_ver)
| eval python_client = if(lower(user_agent) == "*python*", 1, 0)
| eval go_client = if(lower(user_agent) == "*go-http-client*", 1, 0)
| eval java_client = if(lower(user_agent) == "*java*", 1, 0)
| eval fb_asn = if(asn == "*FACEBOOK*", 1, 0)
| eval google_asn = if(asn == "*GOOGLE*", 1, 0)
| eval ms_asn = if(asn == "*MICROSOFT*", 1, 0)
| eval huawei_asn = if(asn == "*HUAWEI CLOUDS*", 1, 0)
| eval yandex_asn = if(asn == "*YANDEX*", 1, 0)
| eval fb_client = if(in(user_agent, "*FBAN/FBIOS;FBDV*", "*facebookexternalhit*", "*cortex/1.0*", "*adreview*"), 1, 0)
| eval google_bot = if(in(user_agent, "*Googlebot-Image/*", "*Googlebot/*"), 1, 0)
| eval bing_bot = if(in(user_agent, "*bingbot/*"), 1, 0)
| eval petal_bot = if(in(user_agent, "*PetalBot*"), 1, 0)
| eval yandex_bot = if(in(user_agent, "*YandexBot/*"), 1, 0)
| eval accept_all = if(len(accept) == 3, 1, 0), keep_alive = if(lower(connection) == "keep-alive", 1, 0)
| eval has_referer = if(len(referer) > 0, 1, 0)
| eval has_sec_fetch_site = if(len(sec_fetch_site) > 0, 1, 0)
| eval header_count = len(split(headers, "\n")), host_header_ip = if(isnotnull(ip(host)), 1, 0)
| eval known_bot = if((google_bot > 0 and google_asn > 0) or (ms_asn > 0 and bing_bot > 0) or (fb_asn > 0 and fb_client > 0) or (huawei_asn > 0 and petal_bot > 0), 1, 0)
| fields _time, log_id, label, pin, header_count, has_sec_fetch_site, has_referer, accept_all, accept_br, accept_sdch, chrome_ver, python_client, go_client, java_client, fb_asn, google_asn, ms_asn, huawei_asn, yandex_asn, fb_client, google_bot, bing_bot, petal_bot, yandex_bot, known_bot
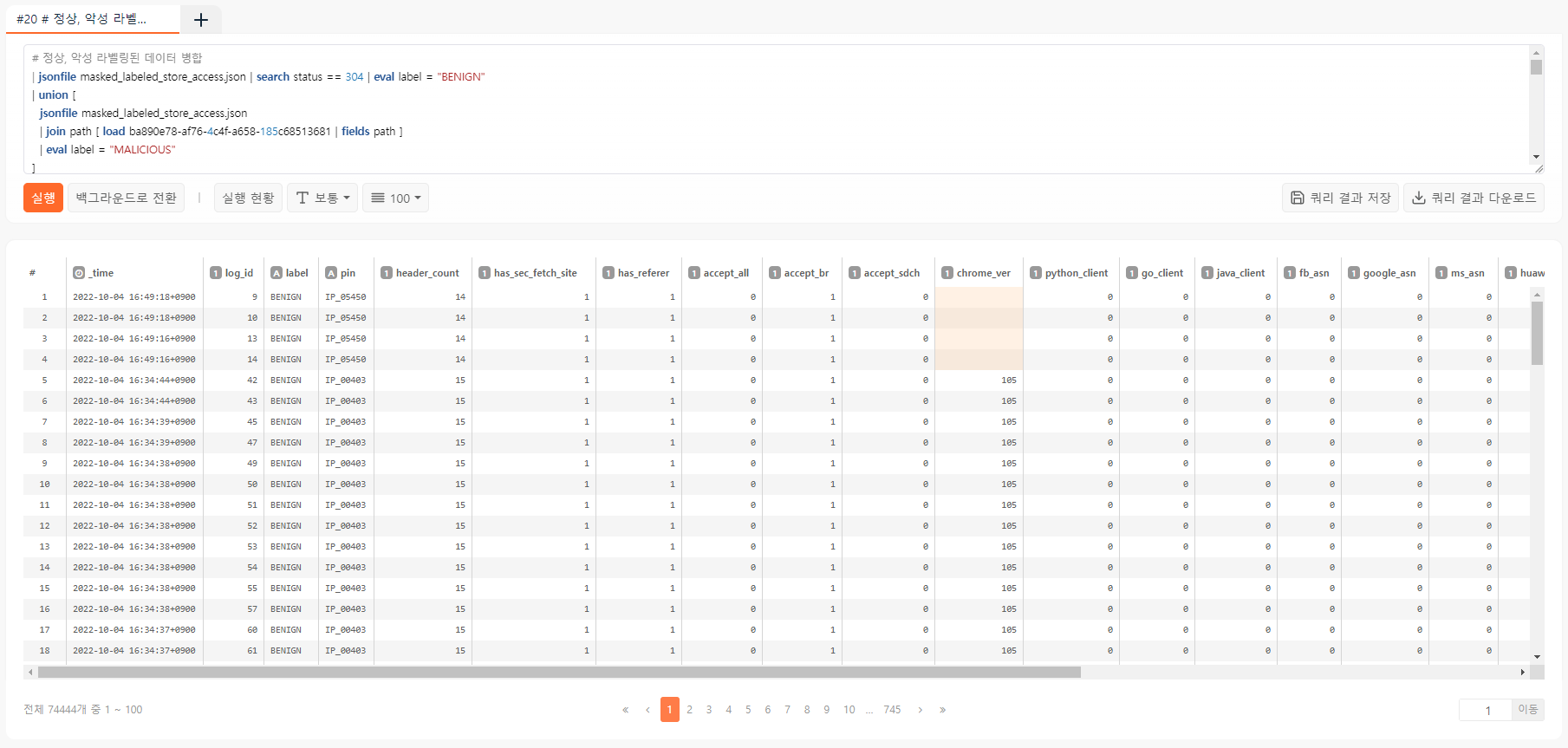
이제 이 결과 데이터에서 _time, log_id, pin을 제외하고 labeled.csv로 다운로드 합니다. 복사-붙여넣기 편의상 이후 모델링은 로그프레소 쉘에서 수행하도록 하겠습니다.
아래와 같이 로드된 데이터를 확인할 수 있습니다.
logpresso> ml.input bot
Input [bot]
---------------------
Type: csv
Size: 74444
Fields
---------------------
label (CATEGORICAL, cardinality 2)
header_count (NUMERIC)
has_sec_fetch_site (NUMERIC)
has_referer (NUMERIC)
accept_all (NUMERIC)
accept_br (NUMERIC)
accept_sdch (NUMERIC)
chrome_ver (NUMERIC)
python_client (NUMERIC)
go_client (NUMERIC)
java_client (NUMERIC)
fb_asn (NUMERIC)
google_asn (NUMERIC)
ms_asn (NUMERIC)
huawei_asn (NUMERIC)
yandex_asn (NUMERIC)
fb_client (NUMERIC)
google_bot (NUMERIC)
bing_bot (NUMERIC)
petal_bot (NUMERIC)
yandex_bot (NUMERIC)
known_bot (NUMERIC)
처음이니 모든 특성을 랜덤포레스트 모델에 투입해봅시다. 학습 목표인 label 변수 앞에는 + 기호로 표시합니다.
logpresso> ml.createModel rforest bot bot
Input [bot]
---------------------
Type: csv
Size: 74444
Fields
---------------------
label (CATEGORICAL, cardinality 2)
header_count (NUMERIC)
has_sec_fetch_site (NUMERIC)
has_referer (NUMERIC)
accept_all (NUMERIC)
accept_br (NUMERIC)
accept_sdch (NUMERIC)
chrome_ver (NUMERIC)
python_client (NUMERIC)
go_client (NUMERIC)
java_client (NUMERIC)
fb_asn (NUMERIC)
google_asn (NUMERIC)
ms_asn (NUMERIC)
huawei_asn (NUMERIC)
yandex_asn (NUMERIC)
fb_client (NUMERIC)
google_bot (NUMERIC)
bing_bot (NUMERIC)
petal_bot (NUMERIC)
yandex_bot (NUMERIC)
known_bot (NUMERIC)
Select Model Fields? +label, header_count, has_sec_fetch_site, has_referer, accept_all, accept_br, accept_sdch, chrome_ver, python_client, go_client, java_client, fb_asn, google_asn, ms_asn, huawei_asn, yandex_asn, fb_client, google_bot, bing_bot, petal_bot, yandex_bot, known_bot
created
학습 명령을 내리고 진행 상태를 확인합니다:
logpresso> ml.fit bot
started
logpresso> ml.tasks
Model Tasks
-------------
[6518b162-3cc8-4b90-9d25-ebee8e80ed67] rforest [bot] progress (load 100.00%, train 40.00%), elapsed 4 secs
이제 모델 정보를 조회하면 변수 중요도와 모델 성능을 확인할 수 있습니다:
logpresso> ml.model bot
Model [bot]
-------------------
Fields
-------------------
[*] label (cardinality: 2)
[ ] header_count
[ ] has_sec_fetch_site
[ ] has_referer
[ ] accept_all
[ ] accept_br
[ ] accept_sdch
[ ] chrome_ver
[ ] python_client
[ ] go_client
[ ] java_client
[ ] fb_asn
[ ] google_asn
[ ] ms_asn
[ ] huawei_asn
[ ] yandex_asn
[ ] fb_client
[ ] google_bot
[ ] bing_bot
[ ] petal_bot
[ ] yandex_bot
[ ] known_bot
-------------------
Hyper Parameters
-------------------
-------------------
Variable Importance
-------------------
accept_all: 39.61612659638045
has_sec_fetch_site: 3.191940042593
header_count: 1.5948264282227802
accept_sdch: 0.43369895792856517
fb_asn: 0.3070484892597034
has_referer: 0.10297082667489638
accept_br: 0.0
chrome_ver: 0.0
python_client: 0.0
go_client: 0.0
java_client: 0.0
google_asn: 0.0
ms_asn: 0.0
huawei_asn: 0.0
yandex_asn: 0.0
fb_client: 0.0
google_bot: 0.0
bing_bot: 0.0
petal_bot: 0.0
yandex_bot: 0.0
known_bot: 0.0
-------------------
Performance
-------------------
Accuracy: 0.9952982267598065
Precision: 0.9952982267598065
Recall: 0.9952982267598065
F1 score: 0.9952982267598065
처음 돌렸는데 정확도가 무려 99.5%라니 이게 정말 통할까요? 전체 데이터에 동일하게 피처 추출한 상태로 rforest 명령어를 추가하여 확인합니다:
jsonfile masked_labeled_store_access.json
| # 피처 추출 영역
| rex field=headers "(?i)user-agent: (?<user_agent>[^\n]+)"
| rex field=headers "(?i)accept-language: (?<accept_lang>[^\n]+)"
| rex field=headers "(?i)accept: (?<accept>[^\n]+)"
| rex field=headers "(?i)connection: (?<connection>[^\n]+)"
| rex field=headers "(?i)host: (?<host>[^\n]+)"
| rex field=headers "(?i)accept-encoding: (?<accept_encoding>[^\n]+)"
| rex field=headers "(?i)chrome/(?<chrome_ver>\d+)"
| rex field=headers "(?i)edg/(?<edge_ver>\d+)"
| rex field=headers "(?i)referer: (?<referer>[^\n]+)"
| rex field=headers "(?i)accept-encoding: (?<accept_encoding>[^\n]+)"
| rex field=headers "(?i)sec-fetch-site: (?<sec_fetch_site>[^\n]+)"
| eval accept_br = if(accept_encoding == "*br*", 1, 0)
| eval accept_sdch = if(accept_encoding == "*sdch*", 1, 0)
| eval chrome_ver = int(chrome_ver), edge_ver = int(edge_ver)
| eval python_client = if(lower(user_agent) == "*python*", 1, 0)
| eval go_client = if(lower(user_agent) == "*go-http-client*", 1, 0)
| eval java_client = if(lower(user_agent) == "*java*", 1, 0)
| eval fb_asn = if(asn == "*FACEBOOK*", 1, 0)
| eval google_asn = if(asn == "*GOOGLE*", 1, 0)
| eval ms_asn = if(asn == "*MICROSOFT*", 1, 0)
| eval huawei_asn = if(asn == "*HUAWEI CLOUDS*", 1, 0)
| eval yandex_asn = if(asn == "*YANDEX*", 1, 0)
| eval fb_client = if(in(user_agent, "*FBAN/FBIOS;FBDV*", "*facebookexternalhit*", "*cortex/1.0*", "*adreview*"), 1, 0)
| eval google_bot = if(in(user_agent, "*Googlebot-Image/*", "*Googlebot/*"), 1, 0)
| eval bing_bot = if(in(user_agent, "*bingbot/*"), 1, 0)
| eval petal_bot = if(in(user_agent, "*PetalBot*"), 1, 0)
| eval yandex_bot = if(in(user_agent, "*YandexBot/*"), 1, 0)
| eval accept_all = if(len(accept) == 3, 1, 0), keep_alive = if(lower(connection) == "keep-alive", 1, 0)
| eval has_referer = if(len(referer) > 0, 1, 0)
| eval has_sec_fetch_site = if(len(sec_fetch_site) > 0, 1, 0)
| eval header_count = len(split(headers, "\n")), host_header_ip = if(isnotnull(ip(host)), 1, 0)
| eval known_bot = if((google_bot > 0 and google_asn > 0) or (ms_asn > 0 and bing_bot > 0) or (fb_asn > 0 and fb_client > 0) or (huawei_asn > 0 and petal_bot > 0), 1, 0)
| # 랜덤포레스트 모델 호출
| rforest model=bot header_count, has_sec_fetch_site, has_referer, accept_all, accept_br, accept_sdch, chrome_ver, python_client, go_client, java_client, fb_asn, google_asn, ms_asn, huawei_asn, yandex_asn, fb_client, google_bot, bing_bot, petal_bot, yandex_bot, known_bot
| fields _time, log_id, _guess, label, pin, header_count, has_sec_fetch_site, has_referer, accept_all, accept_br, accept_sdch, chrome_ver, python_client, go_client, java_client, fb_asn, google_asn, ms_asn, huawei_asn, yandex_asn, fb_client, google_bot, bing_bot, petal_bot, yandex_bot, known_bot
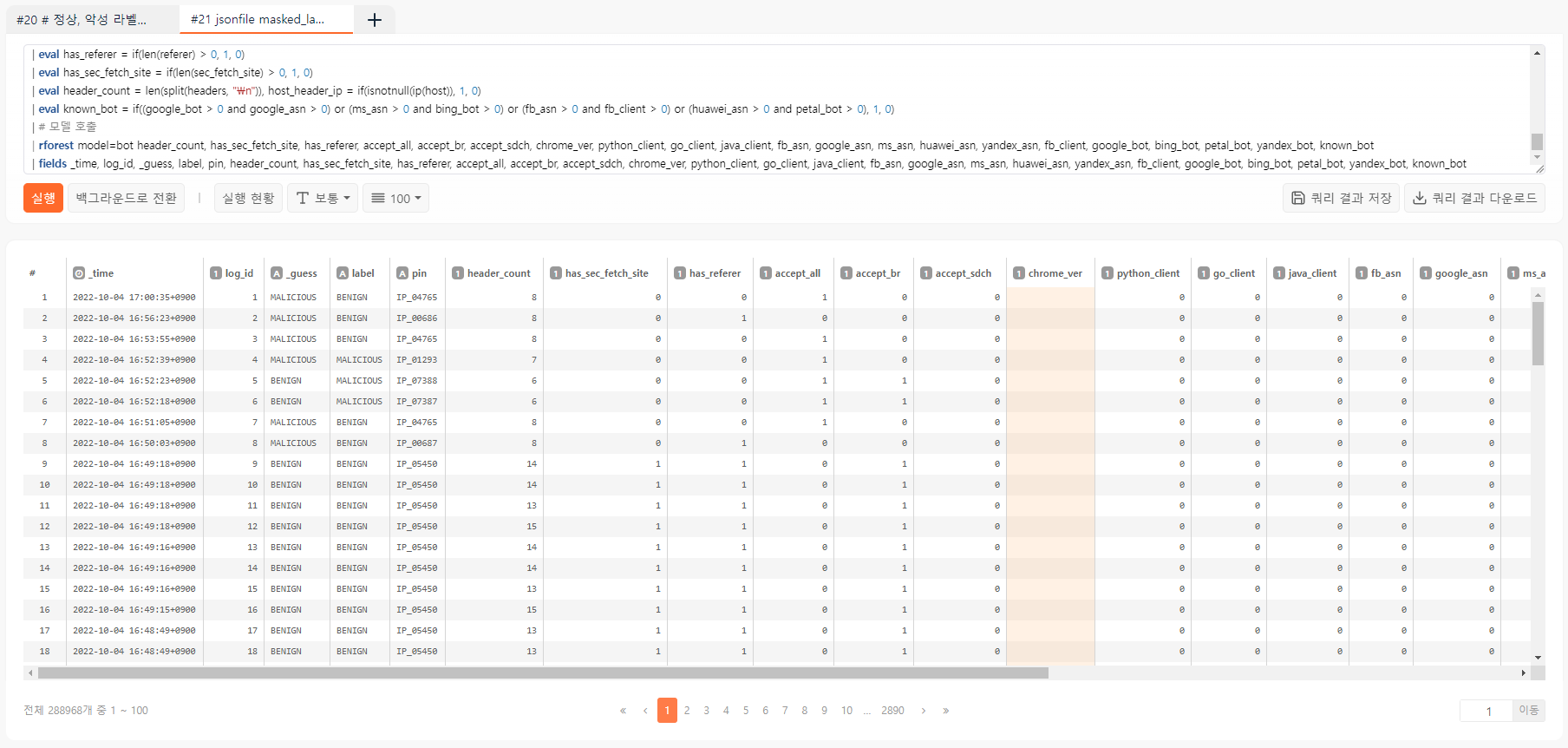
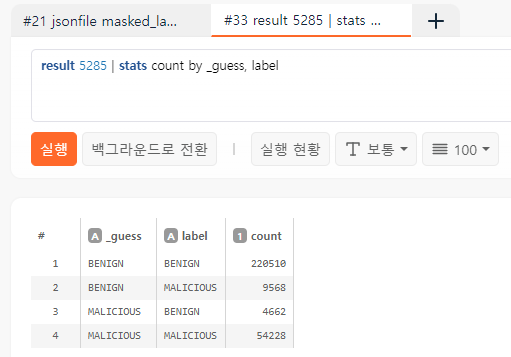
랜덤포레스트 모델이 분류한 결과는 _guess 필드에 출력됩니다. 일단 시작부터 틀린 것이 보이니 뒤에 stats count by _guess, label 을 추가하여 혼동행렬 (Confusion Matrix)을 계산해봅시다.
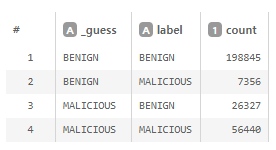
테스트할 때는 99.5%인 줄 알았는데 전체 데이터에 대해서 돌려보니 88% 밖에 안 됩니다. 뭐가 잘못된 것일까요? 모델은 MALICIOUS라고 답했는데 BENIGN이었던 데이터들을 확인해봅시다.
jsonfile masked_labeled_store_access.json
| # 피처 추출 영역
| rex field=headers "(?i)user-agent: (?<user_agent>[^\n]+)"
| rex field=headers "(?i)accept-language: (?<accept_lang>[^\n]+)"
| rex field=headers "(?i)accept: (?<accept>[^\n]+)"
| rex field=headers "(?i)connection: (?<connection>[^\n]+)"
| rex field=headers "(?i)host: (?<host>[^\n]+)"
| rex field=headers "(?i)accept-encoding: (?<accept_encoding>[^\n]+)"
| rex field=headers "(?i)chrome/(?<chrome_ver>\d+)"
| rex field=headers "(?i)edg/(?<edge_ver>\d+)"
| rex field=headers "(?i)referer: (?<referer>[^\n]+)"
| rex field=headers "(?i)accept-encoding: (?<accept_encoding>[^\n]+)"
| rex field=headers "(?i)sec-fetch-site: (?<sec_fetch_site>[^\n]+)"
| eval accept_br = if(accept_encoding == "*br*", 1, 0)
| eval accept_sdch = if(accept_encoding == "*sdch*", 1, 0)
| eval chrome_ver = int(chrome_ver), edge_ver = int(edge_ver)
| eval python_client = if(lower(user_agent) == "*python*", 1, 0)
| eval go_client = if(lower(user_agent) == "*go-http-client*", 1, 0)
| eval java_client = if(lower(user_agent) == "*java*", 1, 0)
| eval fb_asn = if(asn == "*FACEBOOK*", 1, 0)
| eval google_asn = if(asn == "*GOOGLE*", 1, 0)
| eval ms_asn = if(asn == "*MICROSOFT*", 1, 0)
| eval huawei_asn = if(asn == "*HUAWEI CLOUDS*", 1, 0)
| eval yandex_asn = if(asn == "*YANDEX*", 1, 0)
| eval fb_client = if(in(user_agent, "*FBAN/FBIOS;FBDV*", "*facebookexternalhit*", "*cortex/1.0*", "*adreview*"), 1, 0)
| eval google_bot = if(in(user_agent, "*Googlebot-Image/*", "*Googlebot/*"), 1, 0)
| eval bing_bot = if(in(user_agent, "*bingbot/*"), 1, 0)
| eval petal_bot = if(in(user_agent, "*PetalBot*"), 1, 0)
| eval yandex_bot = if(in(user_agent, "*YandexBot/*"), 1, 0)
| eval accept_all = if(len(accept) == 3, 1, 0), keep_alive = if(lower(connection) == "keep-alive", 1, 0)
| eval has_referer = if(len(referer) > 0, 1, 0)
| eval has_sec_fetch_site = if(len(sec_fetch_site) > 0, 1, 0)
| eval header_count = len(split(headers, "\n")), host_header_ip = if(isnotnull(ip(host)), 1, 0)
| eval known_bot = if((google_bot > 0 and google_asn > 0) or (ms_asn > 0 and bing_bot > 0) or (fb_asn > 0 and fb_client > 0) or (huawei_asn > 0 and petal_bot > 0), 1, 0)
| # 모델 호출
| rforest model=bot header_count, has_sec_fetch_site, has_referer, accept_all, accept_br, accept_sdch, chrome_ver, python_client, go_client, java_client, fb_asn, google_asn, ms_asn, huawei_asn, yandex_asn, fb_client, google_bot, bing_bot, petal_bot, yandex_bot, known_bot
| fields _time, log_id, _guess, label, pin, user_agent, headers, header_count, has_sec_fetch_site, has_referer, accept_all, accept_br, accept_sdch, chrome_ver, python_client, go_client, java_client, fb_asn, google_asn, ms_asn, huawei_asn, yandex_asn, fb_client, google_bot, bing_bot, petal_bot, yandex_bot, known_bot
| # 오탐 결과만 선별
| search _guess == "MALICIOUS" and label == "BENIGN"
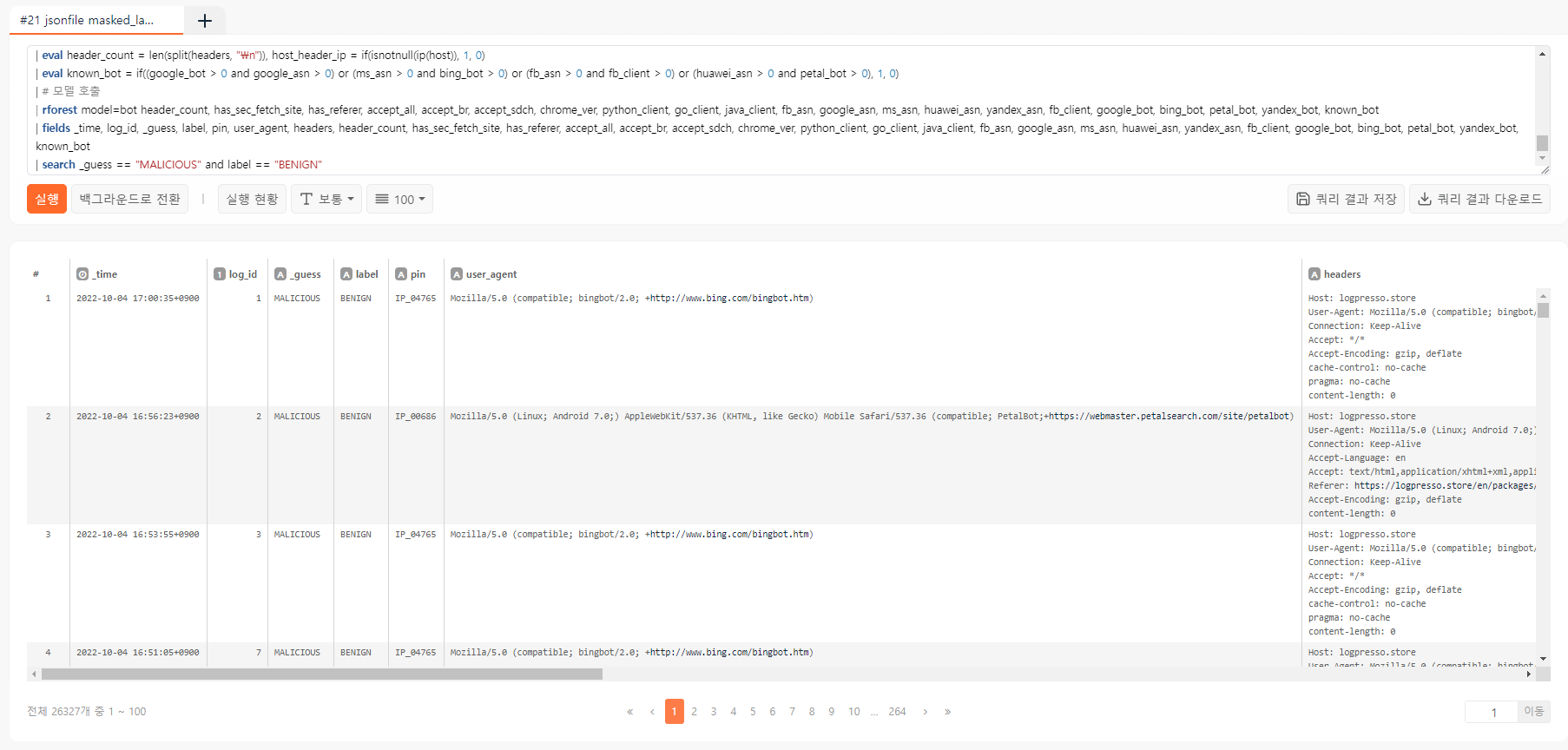
보아하니 검색엔진 봇들이 모두 악성으로 분류된 것 같습니다. _guess == "MALICIOUS" and label == "BENIGN” 결과를 대상으로 한 번 통계를 내보겠습니다:
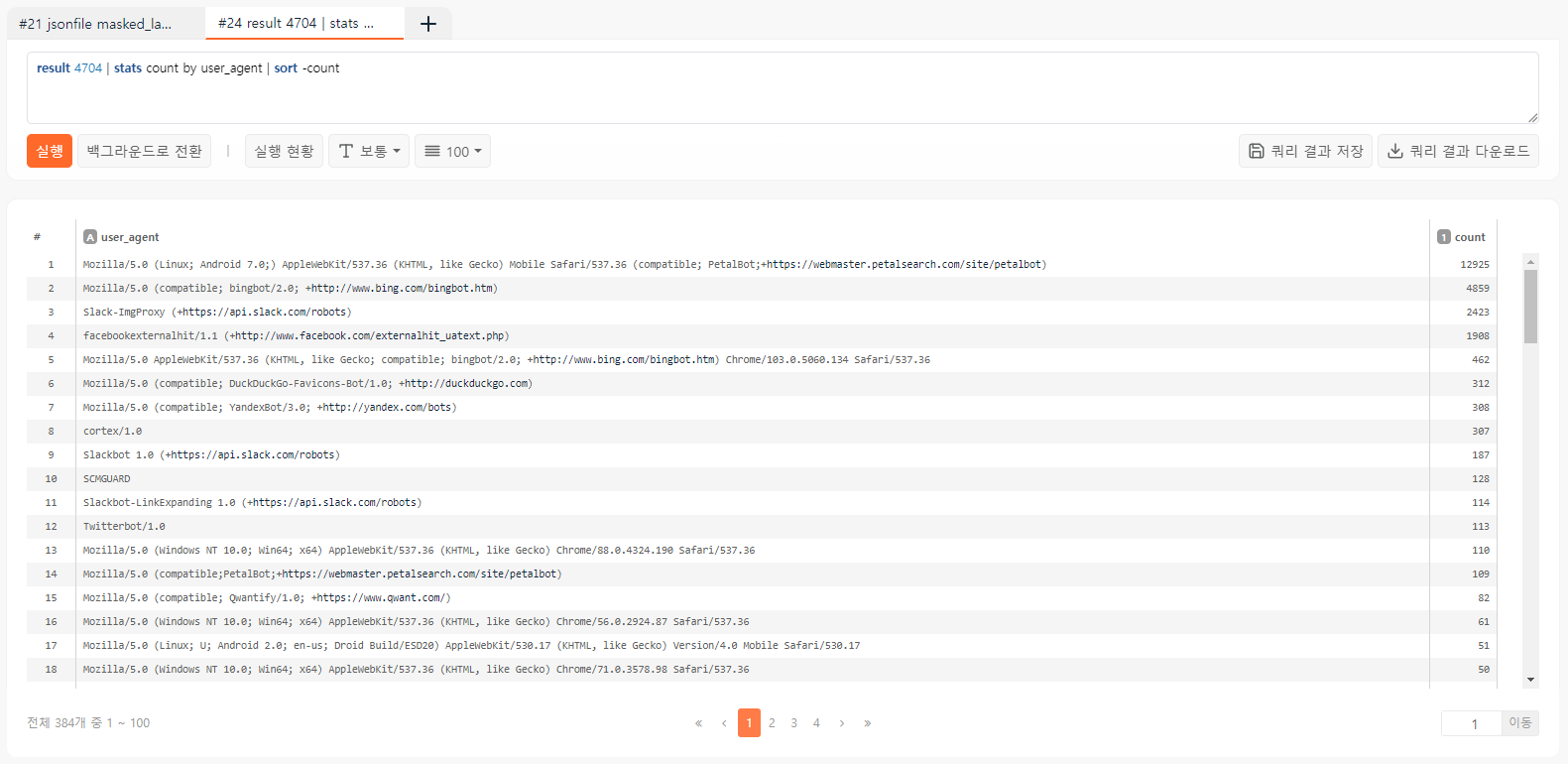
오탐 26327건 중에 PetalBot, bingbot, Slack-ImgProxy, facebookexternalhit 정도만 제대로 처리되더라도 22577건, 즉, 오탐의 85%를 제거할 수 있습니다. 그런데 이 검색엔진 관련된 피처를 빠뜨렸던게 아닙니다. 왜 이런 일이 벌어졌을까요? 이 때 모델 정보의 변수 중요도(Variable Importance)를 다시 확인해봐야 합니다.
-------------------
Variable Importance
-------------------
accept_all: 39.61612659638045
has_sec_fetch_site: 3.191940042593
header_count: 1.5948264282227802
accept_sdch: 0.43369895792856517
fb_asn: 0.3070484892597034
has_referer: 0.10297082667489638
accept_br: 0.0
chrome_ver: 0.0
python_client: 0.0
go_client: 0.0
java_client: 0.0
google_asn: 0.0
ms_asn: 0.0
huawei_asn: 0.0
yandex_asn: 0.0
fb_client: 0.0
google_bot: 0.0
bing_bot: 0.0
petal_bot: 0.0
yandex_bot: 0.0
known_bot: 0.0
accept_all 특성이 지배적이고, fb_asn 외의 검색엔진 관련된 변수는 모델에 전혀 사용되지 않은 것처럼 보입니다. 한 번 이전의 학습 데이터에서 known_bot 분포를 확인해봐야겠습니다.
# 정상, 악성 라벨링된 데이터 병합
| jsonfile masked_labeled_store_access.json | search status == 304 | eval label = "BENIGN"
| union [
jsonfile masked_labeled_store_access.json
| join path [ load ba890e78-af76-4c4f-a658-185c68513681 | fields path ]
| eval label = "MALICIOUS"
]
| # 피처 추출 영역
| rex field=headers "(?i)user-agent: (?<user_agent>[^\n]+)"
| rex field=headers "(?i)accept-language: (?<accept_lang>[^\n]+)"
| rex field=headers "(?i)accept: (?<accept>[^\n]+)"
| rex field=headers "(?i)connection: (?<connection>[^\n]+)"
| rex field=headers "(?i)host: (?<host>[^\n]+)"
| rex field=headers "(?i)accept-encoding: (?<accept_encoding>[^\n]+)"
| rex field=headers "(?i)chrome/(?<chrome_ver>\d+)"
| rex field=headers "(?i)edg/(?<edge_ver>\d+)"
| rex field=headers "(?i)referer: (?<referer>[^\n]+)"
| rex field=headers "(?i)accept-encoding: (?<accept_encoding>[^\n]+)"
| rex field=headers "(?i)sec-fetch-site: (?<sec_fetch_site>[^\n]+)"
| eval accept_br = if(accept_encoding == "*br*", 1, 0)
| eval accept_sdch = if(accept_encoding == "*sdch*", 1, 0)
| eval chrome_ver = int(chrome_ver), edge_ver = int(edge_ver)
| eval python_client = if(lower(user_agent) == "*python*", 1, 0)
| eval go_client = if(lower(user_agent) == "*go-http-client*", 1, 0)
| eval java_client = if(lower(user_agent) == "*java*", 1, 0)
| eval fb_asn = if(asn == "*FACEBOOK*", 1, 0)
| eval google_asn = if(asn == "*GOOGLE*", 1, 0)
| eval ms_asn = if(asn == "*MICROSOFT*", 1, 0)
| eval huawei_asn = if(asn == "*HUAWEI CLOUDS*", 1, 0)
| eval yandex_asn = if(asn == "*YANDEX*", 1, 0)
| eval fb_client = if(in(user_agent, "*FBAN/FBIOS;FBDV*", "*facebookexternalhit*", "*cortex/1.0*", "*adreview*"), 1, 0)
| eval google_bot = if(in(user_agent, "*Googlebot-Image/*", "*Googlebot/*"), 1, 0)
| eval bing_bot = if(in(user_agent, "*bingbot/*"), 1, 0)
| eval petal_bot = if(in(user_agent, "*PetalBot*"), 1, 0)
| eval yandex_bot = if(in(user_agent, "*YandexBot/*"), 1, 0)
| eval accept_all = if(len(accept) == 3, 1, 0), keep_alive = if(lower(connection) == "keep-alive", 1, 0)
| eval has_referer = if(len(referer) > 0, 1, 0)
| eval has_sec_fetch_site = if(len(sec_fetch_site) > 0, 1, 0)
| eval header_count = len(split(headers, "\n")), host_header_ip = if(isnotnull(ip(host)), 1, 0)
| eval known_bot = if((google_bot > 0 and google_asn > 0) or (ms_asn > 0 and bing_bot > 0) or (fb_asn > 0 and fb_client > 0) or (huawei_asn > 0 and petal_bot > 0), 1, 0)
| fields _time, log_id, label, pin, path, headers, header_count, has_sec_fetch_site, has_referer, accept_all, accept_br, accept_sdch, chrome_ver, python_client, go_client, java_client, fb_asn, google_asn, ms_asn, huawei_asn, yandex_asn, fb_client, google_bot, bing_bot, petal_bot, yandex_bot, known_bot
| # known_bot 통계
| pivot count rows known_bot cols label
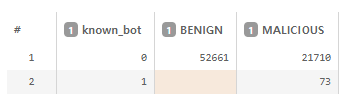
known_bot이 1인 경우 오히려 73건 모두 악성으로 라벨링되어 있습니다. 아까 404 응답에 대해 확실한 공격으로 분류했었는데 뭔가 잘못된듯 합니다.
원본을 확인하니 페이스북에서 포스팅할 때 경로 입력 과정의 오타로 인해 404 응답 처리된 로그들이 있었고 그것들이 모두 악성으로 분류되었다는 점을 확인할 수 있습니다. 그 외에 bing 봇의 atom.xml, sitemaps.xml 요청에 대한 404 응답도 모두 악성으로 잘못 분류되었습니다.
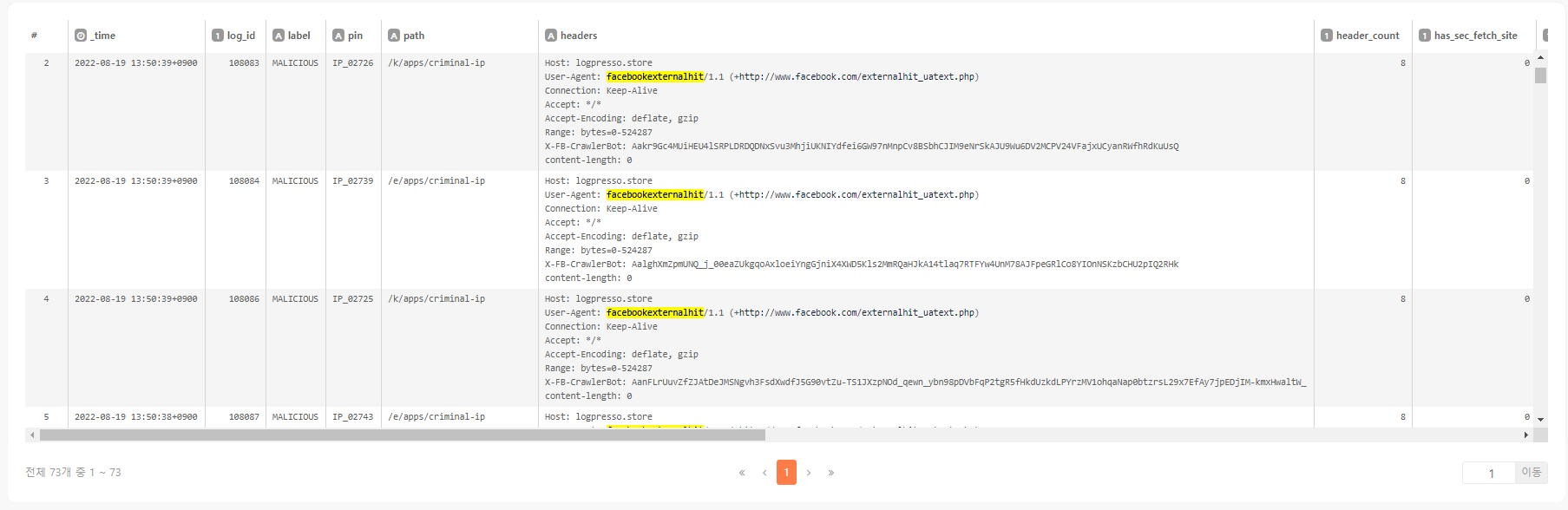
그 외에 Slack도 known_bot으로 분류해야 하는데, Slack은 AWS를 사용하므로 IP 주소로 특정할 수 밖에 없습니다. 1444건이 출력되는 아래의 쿼리 결과를 저장합니다.
이것들을 모두 반영해서 학습 데이터를 다시 정리합니다.
# 정상, 악성 라벨링된 데이터 병합
| jsonfile masked_labeled_store_access.json | search status == 304 | eval label = "BENIGN"
| # 슬랙 known_bot 정상 데이터 추가
| union [
jsonfile masked_labeled_store_access.json
| search headers == "*Slack-*"
| eval known_bot=1, label = "BENIGN" ]
| # 악성 분류 데이터에서 facebook이나 bingbot은 정상으로 재분류
| union [
jsonfile masked_labeled_store_access.json
| join path [ load ba890e78-af76-4c4f-a658-185c68513681 | fields path ]
| rex field=headers "(?i)user-agent: (?<user_agent>[^\n]+)"
| eval label = if(user_agent == "*facebookexternalhit*" or user_agent == "*bingbot*", "BENIGN", "MALICIOUS") ]
| # 피처 추출 영역
| rex field=headers "(?i)user-agent: (?<user_agent>[^\n]+)"
| rex field=headers "(?i)accept-language: (?<accept_lang>[^\n]+)"
| rex field=headers "(?i)accept: (?<accept>[^\n]+)"
| rex field=headers "(?i)connection: (?<connection>[^\n]+)"
| rex field=headers "(?i)host: (?<host>[^\n]+)"
| rex field=headers "(?i)accept-encoding: (?<accept_encoding>[^\n]+)"
| rex field=headers "(?i)chrome/(?<chrome_ver>\d+)"
| rex field=headers "(?i)edg/(?<edge_ver>\d+)"
| rex field=headers "(?i)referer: (?<referer>[^\n]+)"
| rex field=headers "(?i)accept-encoding: (?<accept_encoding>[^\n]+)"
| rex field=headers "(?i)sec-fetch-site: (?<sec_fetch_site>[^\n]+)"
| eval accept_br = if(accept_encoding == "*br*", 1, 0)
| eval accept_sdch = if(accept_encoding == "*sdch*", 1, 0)
| eval chrome_ver = int(chrome_ver), edge_ver = int(edge_ver)
| eval python_client = if(lower(user_agent) == "*python*", 1, 0)
| eval go_client = if(lower(user_agent) == "*go-http-client*", 1, 0)
| eval java_client = if(lower(user_agent) == "*java*", 1, 0)
| eval fb_asn = if(asn == "*FACEBOOK*", 1, 0)
| eval google_asn = if(asn == "*GOOGLE*", 1, 0)
| eval ms_asn = if(asn == "*MICROSOFT*", 1, 0)
| eval huawei_asn = if(asn == "*HUAWEI CLOUDS*", 1, 0)
| eval yandex_asn = if(asn == "*YANDEX*", 1, 0)
| eval fb_client = if(in(user_agent, "*FBAN/FBIOS;FBDV*", "*facebookexternalhit*", "*cortex/1.0*", "*adreview*"), 1, 0)
| eval google_bot = if(in(user_agent, "*Googlebot-Image/*", "*Googlebot/*"), 1, 0)
| eval bing_bot = if(in(user_agent, "*bingbot/*"), 1, 0)
| eval petal_bot = if(in(user_agent, "*PetalBot*"), 1, 0)
| eval yandex_bot = if(in(user_agent, "*YandexBot/*"), 1, 0)
| eval accept_all = if(len(accept) == 3, 1, 0), keep_alive = if(lower(connection) == "keep-alive", 1, 0)
| eval has_referer = if(len(referer) > 0, 1, 0)
| eval has_sec_fetch_site = if(len(sec_fetch_site) > 0, 1, 0)
| eval header_count = len(split(headers, "\n")), host_header_ip = if(isnotnull(ip(host)), 1, 0)
| eval known_bot = if((google_bot > 0 and google_asn > 0) or (ms_asn > 0 and bing_bot > 0) or (fb_asn > 0 and fb_client > 0) or (huawei_asn > 0 and petal_bot > 0), 1, nvl(known_bot, 0))
| fields _time, log_id, label, pin, header_count, has_sec_fetch_site, has_referer, accept_all, accept_br, accept_sdch, chrome_ver, python_client, go_client, java_client, fb_asn, google_asn, ms_asn, huawei_asn, yandex_asn, fb_client, google_bot, bing_bot, petal_bot, yandex_bot, known_bot
모델 데이터를 다시 적재하고 학습합니다:
logpresso> ml.addCsvInput bot_fixed labeled_fixed.csv
added
logpresso> ml.createModel rforest bot2 bot_fixed
Input [bot_fixed]
---------------------
Type: csv
Size: 76867
Fields
---------------------
label (CATEGORICAL, cardinality 2)
header_count (NUMERIC)
has_sec_fetch_site (NUMERIC)
has_referer (NUMERIC)
accept_all (NUMERIC)
accept_br (NUMERIC)
accept_sdch (NUMERIC)
chrome_ver (NUMERIC)
python_client (NUMERIC)
go_client (NUMERIC)
java_client (NUMERIC)
fb_asn (NUMERIC)
google_asn (NUMERIC)
ms_asn (NUMERIC)
huawei_asn (NUMERIC)
yandex_asn (NUMERIC)
fb_client (NUMERIC)
google_bot (NUMERIC)
bing_bot (NUMERIC)
petal_bot (NUMERIC)
yandex_bot (NUMERIC)
known_bot (NUMERIC)
Select Model Fields? +label, header_count, has_sec_fetch_site, has_referer, accept_all, accept_br, accept_sdch, chrome_ver, python_client, go_c
lient, java_client, fb_asn, google_asn, ms_asn, huawei_asn, yandex_asn, fb_client, google_bot, bing_bot, petal_bot, yandex_bot, known_bot
created
logpresso> ml.fit bot2
started
logpresso> ml.tasks
Model Tasks
-------------
[5fc1a68a-4a3b-4810-ab7a-9608212ed480] rforest [bot2] progress (load 100.00%, train 30.00%), elapsed 4 secs
새로 학습된 모델의 정확도는 어떤지 확인해봅니다:
logpresso> ml.model bot2
Model [bot2]
-------------------
Fields
-------------------
[*] label (cardinality: 2)
[ ] header_count
[ ] has_sec_fetch_site
[ ] has_referer
[ ] accept_all
[ ] accept_br
[ ] accept_sdch
[ ] chrome_ver
[ ] python_client
[ ] go_client
[ ] java_client
[ ] fb_asn
[ ] google_asn
[ ] ms_asn
[ ] huawei_asn
[ ] yandex_asn
[ ] fb_client
[ ] google_bot
[ ] bing_bot
[ ] petal_bot
[ ] yandex_bot
[ ] known_bot
-------------------
Hyper Parameters
-------------------
-------------------
Variable Importance
-------------------
accept_sdch: 56.48699943927758
yandex_bot: 22.787406812885486
accept_all: 21.551910129425835
has_sec_fetch_site: 4.790621163151365
header_count: 1.281179927083544
chrome_ver: 0.20474131367645387
has_referer: 0.20081416801138077
yandex_asn: 0.04364948596639201
google_asn: 0.03269234686475131
accept_br: 0.0
python_client: 0.0
go_client: 0.0
java_client: 0.0
fb_asn: 0.0
ms_asn: 0.0
huawei_asn: 0.0
fb_client: 0.0
google_bot: 0.0
bing_bot: 0.0
petal_bot: 0.0
known_bot: 0.0
-------------------
Performance
-------------------
Accuracy: 0.9879659142652703
Precision: 0.9879659142652703
Recall: 0.988356208937748
F1 score: 0.9881610230627685
F1 점수는 98.8%로 이전보다 오히려 약간 떨어졌는데요. 이제 전체 데이터에 대해 새로 만든 bot2 모델을 돌려서 다시 결과를 확인할 것입니다. 주의할 점은 학습할 때 Slack을 알려진 봇으로 처리했으니 모델 입력 시 동일한 처리를 추가해야 한다는 것입니다. rforest 명령어의 model 이름도 bot2 로 변경해야 합니다.
jsonfile masked_labeled_store_access.json
| # 피처 추출 영역
| rex field=headers "(?i)user-agent: (?<user_agent>[^\n]+)"
| rex field=headers "(?i)accept-language: (?<accept_lang>[^\n]+)"
| rex field=headers "(?i)accept: (?<accept>[^\n]+)"
| rex field=headers "(?i)connection: (?<connection>[^\n]+)"
| rex field=headers "(?i)host: (?<host>[^\n]+)"
| rex field=headers "(?i)accept-encoding: (?<accept_encoding>[^\n]+)"
| rex field=headers "(?i)chrome/(?<chrome_ver>\d+)"
| rex field=headers "(?i)edg/(?<edge_ver>\d+)"
| rex field=headers "(?i)referer: (?<referer>[^\n]+)"
| rex field=headers "(?i)accept-encoding: (?<accept_encoding>[^\n]+)"
| rex field=headers "(?i)sec-fetch-site: (?<sec_fetch_site>[^\n]+)"
| eval accept_br = if(accept_encoding == "*br*", 1, 0)
| eval accept_sdch = if(accept_encoding == "*sdch*", 1, 0)
| eval chrome_ver = int(chrome_ver), edge_ver = int(edge_ver)
| eval python_client = if(lower(user_agent) == "*python*", 1, 0)
| eval go_client = if(lower(user_agent) == "*go-http-client*", 1, 0)
| eval java_client = if(lower(user_agent) == "*java*", 1, 0)
| eval fb_asn = if(asn == "*FACEBOOK*", 1, 0)
| eval google_asn = if(asn == "*GOOGLE*", 1, 0)
| eval ms_asn = if(asn == "*MICROSOFT*", 1, 0)
| eval huawei_asn = if(asn == "*HUAWEI CLOUDS*", 1, 0)
| eval yandex_asn = if(asn == "*YANDEX*", 1, 0)
| eval fb_client = if(in(user_agent, "*FBAN/FBIOS;FBDV*", "*facebookexternalhit*", "*cortex/1.0*", "*adreview*"), 1, 0)
| eval google_bot = if(in(user_agent, "*Googlebot-Image/*", "*Googlebot/*"), 1, 0)
| eval bing_bot = if(in(user_agent, "*bingbot/*"), 1, 0)
| eval petal_bot = if(in(user_agent, "*PetalBot*"), 1, 0)
| eval yandex_bot = if(in(user_agent, "*YandexBot/*"), 1, 0)
| eval accept_all = if(len(accept) == 3, 1, 0), keep_alive = if(lower(connection) == "keep-alive", 1, 0)
| eval has_referer = if(len(referer) > 0, 1, 0)
| eval has_sec_fetch_site = if(len(sec_fetch_site) > 0, 1, 0)
| eval header_count = len(split(headers, "\n")), host_header_ip = if(isnotnull(ip(host)), 1, 0)
| eval known_bot = if((google_bot > 0 and google_asn > 0) or (ms_asn > 0 and bing_bot > 0) or (fb_asn > 0 and fb_client > 0) or (huawei_asn > 0 and petal_bot > 0), 1, 0)
| # 추론 시에도 슬랙의 known_bot 처리를 추가해야 함
| eval known_bot = if(user_agent == "*Slack-*", 1, known_bot)
| # 랜덤포레스트 모델 호출
| rforest model=bot2 header_count, has_sec_fetch_site, has_referer, accept_all, accept_br, accept_sdch, chrome_ver, python_client, go_client, java_client, fb_asn, google_asn, ms_asn, huawei_asn, yandex_asn, fb_client, google_bot, bing_bot, petal_bot, yandex_bot, known_bot
| fields _time, log_id, _guess, label, pin, header_count, has_sec_fetch_site, has_referer, accept_all, accept_br, accept_sdch, chrome_ver, python_client, go_client, java_client, fb_asn, google_asn, ms_asn, huawei_asn, yandex_asn, fb_client, google_bot, bing_bot, petal_bot, yandex_bot, known_bot
이제 정확도가 95%로 개선되었습니다.
정리
전체 데이터의 라벨링은 휴리스틱으로 일괄 처리했기 때문에, 앞서 봤던 것처럼 일부 오류가 있을 수 있습니다. 적용된 방법은 아래와 같습니다:
- 다수의 세부 페이지 접속에서 단 한 번의 오류도 유발하지 않은 브라우저 접속 로그
- 크리미널 IP 서비스(https://criminalip.io/)에서 평판 조회 결과가 inbound_score 혹은 outbound_score가 4 이상인 경우 악성 IP로 일괄 분류
- 정상 서비스 경로라도 악성 데이터를 POST한 경우 해당 IP의 모든 로그를 악성으로 분류
- 알려진 스캐너, 흔하지 않은 크롤러, 프로그래밍 방식으로 접근한 모든 클라이언트 로그를 악성으로 분류
이 글에서는 HTTP 헤더에서 특성을 추출하여 사용했지만, 일반적인 웹 서버의 로그 세팅에서는 통상 헤더 전체가 기록되지 않습니다. 기본적인 웹 로그 세팅에서 알려지지 않은 웹 공격을 탐지하는게 목적이라면, 로그프레소의 특허 제10-2096785처럼 로그의 시퀀스를 학습하는 것이 좋습니다. 웹 방화벽은 공격 탐지 시 HTTP 헤더 정보를 전달하지만, 탐지 결과의 정오탐 분류가 목적이라면 HTTP 본문을 포함한 페이로드 전체를 대상으로 모델링하는 것이 효과적입니다.
개별 웹 로그에 대해 모델이 추론한 결과로 경보를 발생시키면 경보의 양 때문에 대응하는데 어려움을 겪을 수 있습니다. 수백만 건의 접속 로그에 대하여 단 1%만 오류가 발생하더라도 1000건 이상의 오탐이 발생할 수 있기 때문입니다. 따라서 출발지 IP 주소로 그룹화하여 경보를 발생시키는 것이 탐지 결과에서 전체적인 맥락을 파악하고 방화벽 등을 통해 위협 IP를 차단 조치하기에 유리합니다.


