통합로그관리(LMS) 시스템이나 통합보안관제(SIEM) 시스템에 방화벽, IPS, 웹 방화벽 등 네트워크 보안 장비를 연동하는 경우, 우리는 20년 이상 UDP를 통한 SYSLOG 전송 프로토콜을 사용해왔습니다. 이는 RFC3164 - The BSD syslog Protocol 문서에 정의된 것으로 대부분의 사람들이 익숙합니다.
UDP를 통한 SYSLOG 전송 방식은 흐름 제어(Flow Control)를 사용하지 않으므로, 수신 시스템의 성능이 느리거나 심지어 장애가 발생하더라도 송신 시스템까지 영향을 미치지 않는다는 장점이 있습니다. 특히 네트워크 장비가 로그로 인해 성능에 영향이 있다면 통신 장애로 귀결되므로, 자연스럽게 UDP 기반 SYSLOG 전송이 매우 선호되어 왔습니다.
그러나 UDP는 프로토콜 수준에서 암호화를 지원하지 않으므로 로그 내용이 그대로 노출될 수 있습니다. 클라우드 기반의 원격 관제 서비스를 구성할 때 전용선이나 VPN이 아닌 인터넷 구간을 통해 네트워크 보안 장비를 직접 SIEM에 접속시켜야 할 경우가 자주 발생합니다. 이런 시나리오에서는 반드시 TLS 채널을 통해 안전하게 로그를 전송하도록 구성해야 합니다.
그런데 TCP 또는 TLS 채널을 통해 로그를 전송할 때 비표준 프로토콜 설계를 종종 보게 됩니다. UDP 소켓에서 수신할 때는 송신한 메시지대로 패킷이 전달되기 때문에 멀티라인 등 어떤 형태라도 의도한 메시지 단위로 로그가 전송됩니다. 반면 TCP 소켓에서는 스트림으로 데이터가 수신되기 때문에, 메시지의 경계를 직접 정의해주어야 합니다.
RFC6587 - Transmission of Syslog Messages over TCP 문서는 2012년에 나왔지만 의외로 이 내용을 알고 있는 사람을 찾아보기가 상당히 어려웠습니다. 그것이 보안 솔루션 개발 시 비표준 구현을 만드는 원인이라 생각되어 오늘 간단히 TCP 프로토콜에서 사용하는 SYSLOG 메시지 프레이밍을 소개하고자 합니다.
Non-Transparent-Framing
레거시 시스템이 오래 전부터 사용하는 방법은 메시지 구분자를 이용하는 것입니다. 개행 문자(Line Feed)를 사용하여 메시지를 구분하는 것이 가장 흔한 방법입니다.
다만 여러 줄로 구성된 로그를 전송할 때는 개행 문자를 구분자로 사용할 수 없습니다. 이런 경우 NULL 문자를 구분자로 사용하기도 합니다.
Octet Counting
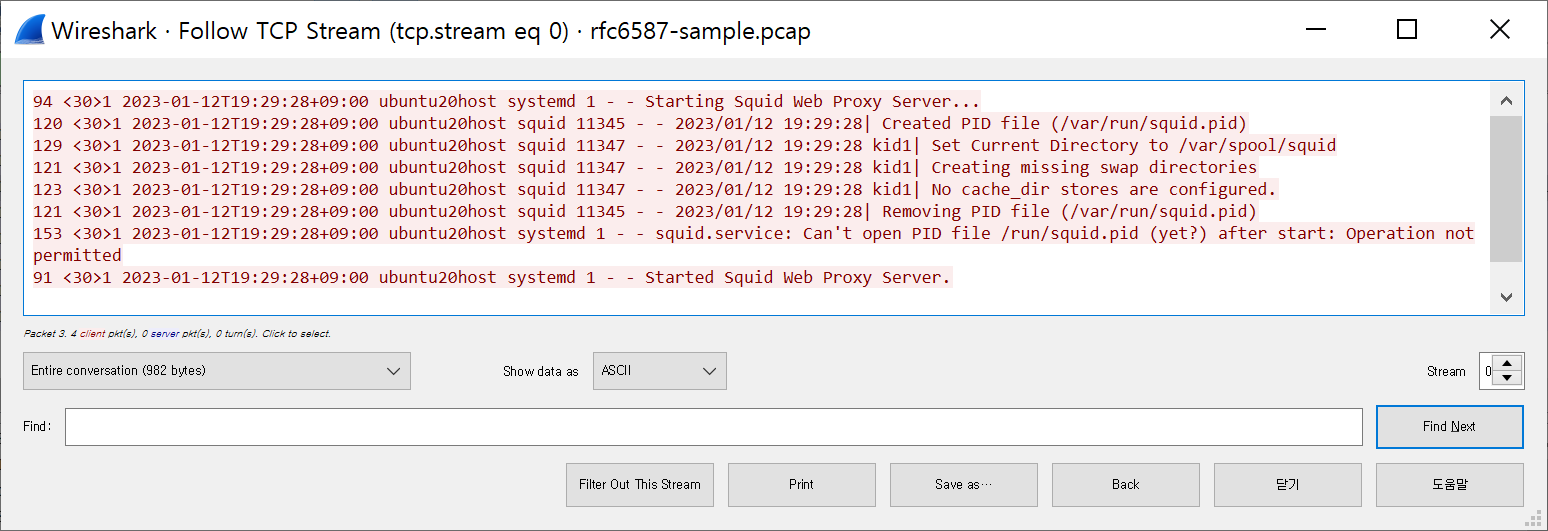
RFC6587이나 TLS 채널을 통한 Syslog 전송을 다룬 RFC5425에 정의된 규칙은 메시지 시작 위치에 10진수로 뒤에 오게 될 페이로드의 길이를 바이트 단위로 기록하는 것입니다.
예를 들어, 이 PCAP 파일의 첫번째 메시지 프레임은 MSG-LEN 94와 공백 문자로 시작하며 이어지는 메시지 텍스트는 <30>부터 Server… 뒤의 개행 (0x0a) 문자까지 94바이트가 이어집니다:
정리
인터넷 규약대로 로그 전송을 구현하면 기존의 많은 시스템에 한 번에 호환시킬 수 있습니다. 반면, 비표준 방식으로 로그를 전송하면 자사의 장비를 새로운 유형의 시스템에 연동해야 할 때마다 많은 시간과 비용을 야기합니다. 이 글이 업계의 상호 운영성을 향상시키는데 도움이 되기를 바랍니다.