로그프레소 소나 4.0.2308.0 버전이 출시되었습니다. 이번 릴리스는 약 140가지의 변경사항을 포함하고 있으며, 로그프레소 엔터프라이즈 제품군 단종 이후 전면적인 세대 교체와 운영 편의성 향상을 목표로 합니다. 이전에 엔터프라이즈에서만 사용 가능하던 기능들은 최대한 빠른 시일 내에 소나 제품군에서 지원할 예정입니다.
통합 빌드
로그프레소 스탠다드, 엔터프라이즈, 소나, 마에스트로 4종의 모델에 따라 별도의 패키지를 구분하여 설치하고 관리하는 것은 그 복잡성으로 인해 운영자와 엔지니어에게 어려움을 가중시키는 문제가 있었습니다. 이에 스탠다드 및 엔터프라이즈는 단종시키고, 단일 서버 패키지로 3종의 모델을 지원하도록 개선했습니다:
- Logpresso Sonar Light: 통합로그 관리
- Logpresso Sonar: 통합보안관제
- Logpresso Maestro: 보안운영 자동화
이에 따라 4.0.2308.0 버전부터는 라이선스 설치만으로 메뉴 구성과 기능 집합이 즉각적으로 변경됩니다.
수집 설정 단순화
이전 버전에서는 수집 모델, 추출 모델, 원본 로그 파서, 정규화 로그 파서, 로그 스키마가 모두 구분되어 있었습니다. 이 때문에 새 유형의 수집기를 정의하려면 5개 메뉴를 오가며 설정해야 하는 어려움이 있었습니다.
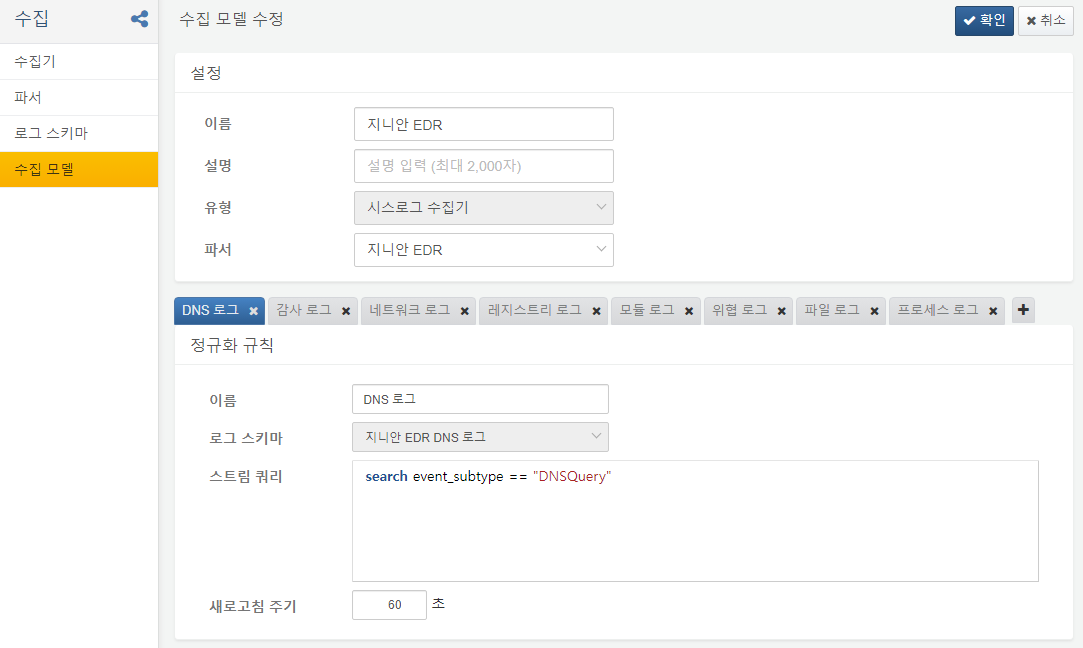
원본 로그 파서와 정규화 로그 파서는 하나의 파서 메뉴로 통합하고, 추출 모델 메뉴는 수집 모델 설정 화면에서 탭으로 즉시 편집할 수 있도록 하였습니다. 이제 파서를 생성하고, 파싱 결과를 확인하면서 로그 스키마를 정의한 후, 수집 모델을 편집하는 이전보다 훨씬 간결한 흐름으로 새 수집 유형을 정의할 수 있게 되었습니다.
앱 기능 향상
통합로그관리 또는 통합보안관제 솔루션을 구축할 때 통상 많은 기간이 수집 설정과 필드 정규화에서 소요됩니다. 모든 필드를 정확하게 파싱하면서도 성능 문제가 없는 정규표현식을 작성하거나, 필드 이름의 공통 표준화를 수행하고, 드릴다운 분석 가능한 대시보드를 설정하기까지 수많은 설정과 검증을 거쳐야 합니다.
이전의 엔터프라이즈 4.0은 최소한의 설정으로 대시보드 시각화까지 구성하는 기능을 선보였습니다. 하지만 지금까지 소나는 필요에 따라 확장된 쿼리 명령어, 파서, 수집기를 사용할 수 있는 기능만을 앱으로 지원해왔습니다.
이번 소나 릴리스부터는 파서, 로그 스키마, 수집 모델, 데이터셋, 위젯, 대시보드 객체를 앱에 내장하여 지원합니다. 즉, 소나에서도 이제 앱을 설치하고 수집기를 추가하기만 하면 즉시 대시보드를 사용할 수 있다는 의미입니다. 로그프레소 스토어에서 제공하는 60종의 앱을 설치하기만 하면 이제 소나에서도 설치 당일 운영을 시작할 수 있습니다.
다만 아직까지는 plugin 디렉터리에 앱을 설치해야 합니다. 다음 릴리스에서는 웹 브라우저에서 클러스터 전체에 앱을 설치 및 관리할 수 있는 기능을 지원할 예정이니 조금만 더 기다려주세요.
매니지드 시큐리티 서비스 지원
LG CNS와 매니지드 탐지 및 대응(MDR) 협업을 진행하면서 다수의 고객사를 효율적으로 관리할 수 있는 프레임워크를 구현하였습니다. “사이트” 개념이 새로 추가되었으며, 자산 IP와 수집기에 사이트를 매핑할 수 있습니다. 로그 수집 시점에 사이트 이름이 태깅되고, 시나리오 탐지 시 티켓에 사이트가 매핑되며, 티켓 목록에서 사이트 단위로 검색 및 대응을 수행할 수 있습니다.
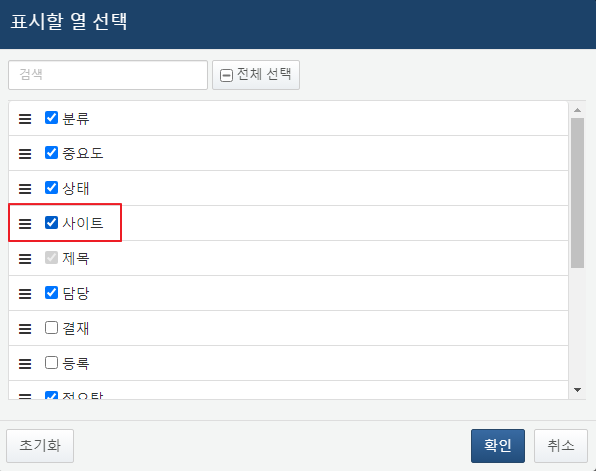
이 뿐 아니라, 티켓에 태그를 추가할 수 있도록 하여 위협 분류 및 대응 상태 가시성을 향상시켰습니다.
성능 모니터
시스템 담당자는 누구나 안정적인 시스템 운영을 목표로 합니다. 그러나 이전의 성능 모니터링은 초심자가 직관적으로 장애 상황을 인지하기 어려웠습니다. 이번 릴리스는 성능 모니터 메뉴를 추가하여 대규모 클러스터에서 장애나 로그 유실 여부를 직관적으로 파악할 수 있도록 개선하였습니다.
예를 들어 아래는 장애 발생 시의 그래프 예입니다.
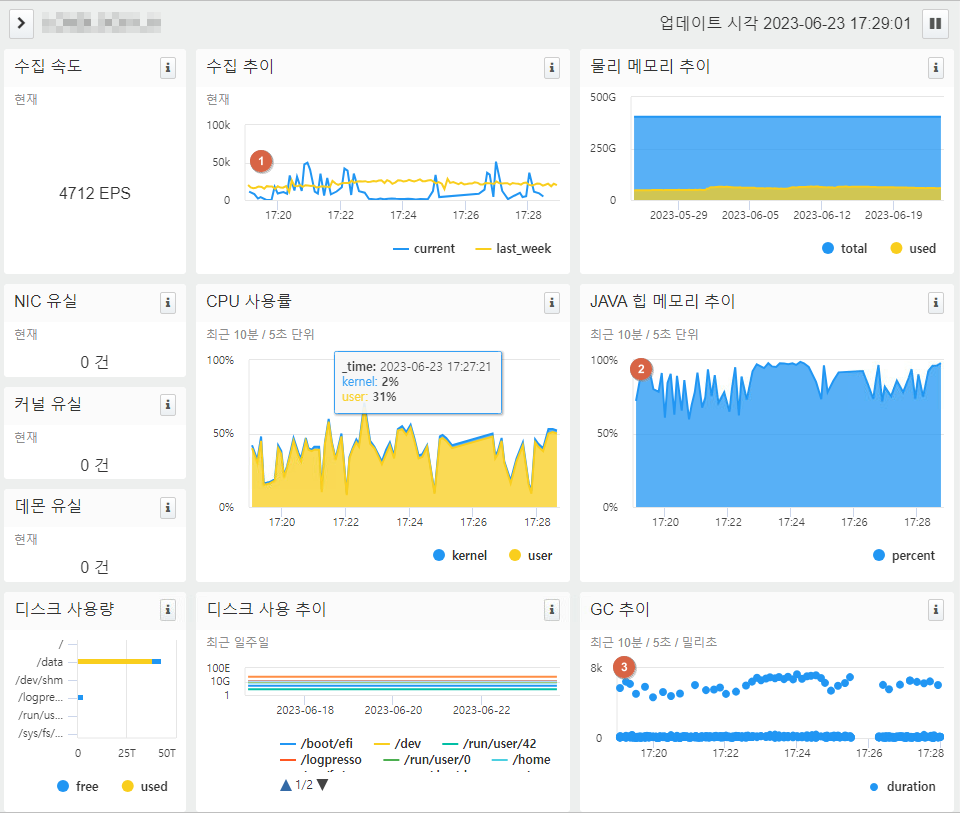
수집 추이는 노란색으로 지난 주 추이를 출력합니다. 1번의 현재 수집 추이와 지난 주 추이를 비교하기만 해도 직관적으로 장애 여부를 파악할 수 있습니다. 특히 2번의 힙 메모리 추이 패턴과 3번의 GC 추이를 보면 현재 힙 메모리 고갈로 인한 장애가 발생하고 있다는 사실을 즉시 파악할 수 있습니다.
이 뿐만 아니라, 네트워크 인터페이스 카드의 패킷 유실, 커널 스택에서의 패킷 유실, 로그프레소 데몬에서의 패킷 유실을 한 눈에 확인할 수 있도록 표시하여, 시스템 운영자가 현재 클러스터 상태가 정상인지 확신을 가질 수 있도록 개선하였습니다.
REST API
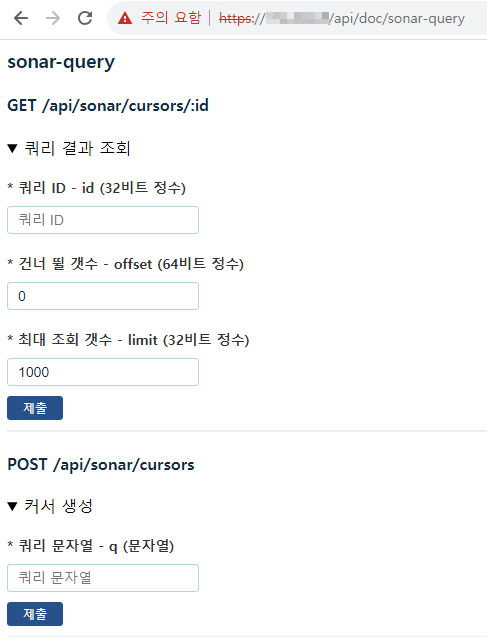
이번 릴리스부터 100가지 이상의 REST API가 지원됩니다. 계정에서 API 키 발급 버튼을 클릭하여 새 API 키를 생성하고 사용할 수 있습니다. 타 SOAR 솔루션 또는 보안포털에서 로그프레소를 연동하려는 경우, 로그프레소 REST API 레퍼런스를 참고하여 즉시 연동하실 수 있습니다.
프로그램을 작성하기 전이라도 웹 브라우저에서 API를 즉시 테스트 할 수 있습니다. https://hostname/api/ 경로로 이동하면 사용 가능한 API 그룹이 표시되고, 각 API 그룹을 클릭하면 아래와 같이 API 테스트 화면이 제공됩니다.
맺음말
이 외에도 매우 많은 기능들이 개선되었습니다. 4.0.2308 릴리스 노트에서 세부사항을 확인해보세요!


